表现 当使用较低版本的 tokenizers 库加载版本较高的 tokenizer.json 时,会出现低版本不兼容高版本 tokenizer.json 的问题。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import jsonfrom huggingface_hub import hf_hub_downloadimport tokenizersfrom tokenizers import Tokenizerprint (f"{tokenizers.__version__ = } " )def load_tokenizer_and_transformers_version (model_id ): tokenizer_filepath = hf_hub_download(repo_id=model_id, filename="tokenizer.json" ) try : tokenizer = Tokenizer.from_file(tokenizer_filepath) print (tokenizer) except Exception as e: print (f"Error loading tokenizer for model {model_id} : {e} " ) config_filepath = hf_hub_download(repo_id=model_id, filename="config.json" ) config = json.load(open (config_filepath, "r" , encoding="utf-8" )) record_version = config.get("transformers_version" , "unknown" ) print (f"Model ID: {model_id} , Transformers Version: {record_version} " ) QWEN3_MODEL_ID = "Qwen/Qwen3-8B" load_tokenizer_and_transformers_version(QWEN3_MODEL_ID) QWEN2_5_MODEL_ID = "Qwen/Qwen2.5-7B-Instruct" load_tokenizer_and_transformers_version(QWEN2_5_MODEL_ID)
兼容性情况如下:
tokenizers 版本
Qwen3-8B (transformers 4.51.0)
Qwen2.5-7B-Instruct (transformers 4.43.1)
0.19.1
❌
✅
0.20.0
✅
✅
0.21.1
✅
✅
报错时信息如下:
1 2 3 4 5 tokenizers.__version__ = '0.19.1' ... File "tokenizers_version/load_qwen3_tokenizer.py", line 13, in load_tokenizer_and_transformers_version tokenizer = Tokenizer.from_file(tokenizer_filepath) Exception: data did not match any variant of untagged enum ModelWrapper at line 757479 column 3
原因 这个报错发生在 tokenizers 库的 tokenizers.abi3.so 中,因为是 native 层报错,所以不会显示 Python 的 traceback 信息。
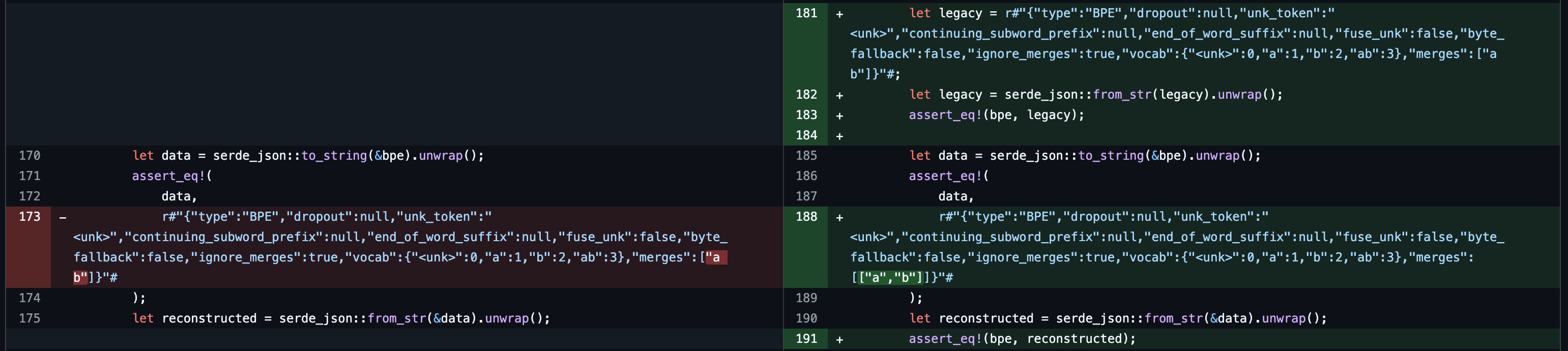
具体原因是 tokenizers 从 0.19.1 升级到 0.20.0 时,tokenizer.json 的格式发生了变化,见 merges cannot handle tokens containing spaces | tokenizers / 909 。为了支持包含空格的 token,merges 字段从之前的 string 类型变成了 pair<string, string> 类型。部分代码如下:
因此,低版本的 tokenizers 无法正确解析高版本的 tokenizer.json 文件。
解决方案
升级 tokenizers 库到 0.20.0 或更高版本即可解决此问题。
如果无法升级版本,可以尝试手动修改 tokenizer.json 文件,将 merges 字段转换为低版本支持的格式(运行时或者离线转换均可),但这可能会导致其他兼容性问题。
代码 blog-demo-codes/tokenizers_version