MiniCPM-O-2_6 模型结构介绍
目的
介绍一下有关 VLM/MLLM 的模型结构,从模型结构上指导模型部署,了解各个模块的作用。
MiniCPM-O-2_6 简介
O 代表了 Omni,含义是全能。MiniCPM-O-2_6 是一个基于 MiniCPM-2 的多模态模型,在之前的 MiniCPM-V-2_6 的基础上增加了额外的多模态能力,包括【语音识别】、【语音生成】的功能。由于语音作为文本嵌入到了 LLM 的输入之中,还可以实现【语音提问图片内容,语音回复】的功能。OpenBMB 官方博客见 MiniCPM-o 2.6: A GPT-4o Level MLLM for Vision, Speech, and Multimodal Live Streaming on Your Phone。
为了实现上面的功能,MiniCPM-O-2_6 一共有四个模块:
- SigLip-400M 视觉编码器:用于提取视觉特征,并映射到 LLM 嵌入空间
- Whisper-medium-300M 语音编码器:用于提取语音特征,也映射到 LLM 嵌入空间
- LLM:基于 Qwen2.5-7B 模型,能够支持多模态输入,但是受限于 LLM 的表征,实际上只生成出文本,不能生成语音。
- ChatTTS-200M:提供语音生成能力,它也是一个基于 LLM 自回归范式的模型,接受文本+语音 ID 作为输入,并生成语音 ID
在训练过程中,预训练主要提供视觉+语音理解能力(Vision Pretraining + Audio Pretraining + Omni Pretraining),后训练提供了语音生成能力(Omni SFT)。

模型结构
视觉编码器
ViT
视觉编码器使用的是 SigLip-400M,一些常用的视觉编码器模型如下:
| ViT | 输入分辨率 | Patch 大小 | 其它 |
|---|---|---|---|
| CLIP: Learning Transferable Visual Models From Natural Language Supervision |
224x224 | 14x14 | openai 最先推出的 CLIP,基于 ViT-B/32 ViT-B/16 Vit-L/14。 |
| SigLip: Sigmoid Loss for Language Image Pretraining |
384x384 | 14x14 | SigLip 使用了跟 CLIP 相同的对比学习方法,但是使用的是 sigmoid 函数作为相似程度区分,CLIP 使用的是 softmax。从结构上看,SigLip 还使用了其他的 vision backbone,包括 ViT-B ViT-L So-400m。 |
CLIP 和 SigLip 都使用了 ViT 作为骨干网络,下面简要介绍一下 ViT 的相关结构。
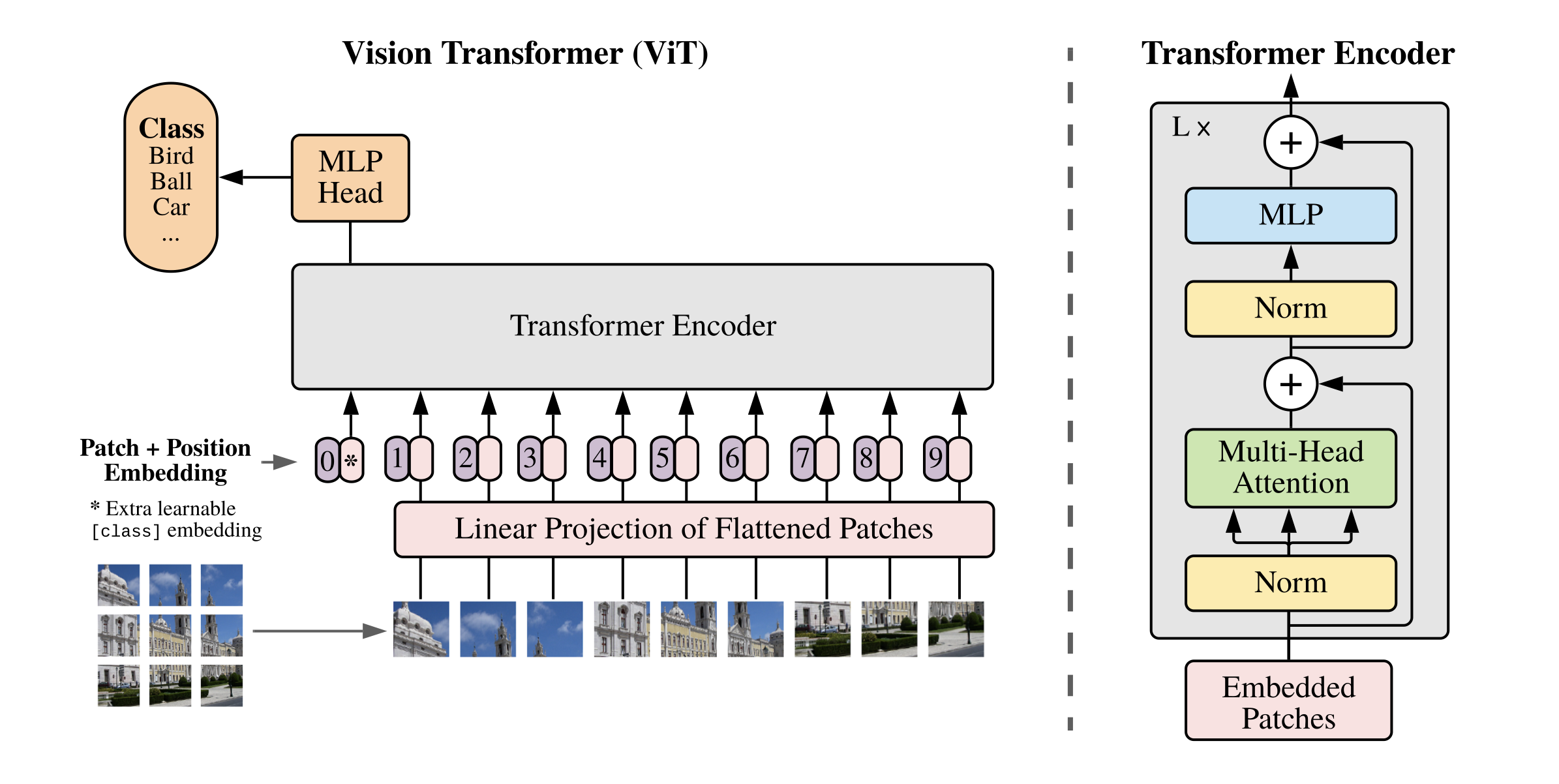
上图是 ViT 的结构示意图,左边的示意图展示了从图像变为嵌入的具体过程,图像嵌入包括三个部分:【Patch Embedding】、【Position Embedding】、【Learnable Embedding】。具体含义如下:
- Patch Embedding:Patch 大小代表了多大的图像像素会被映射为单个 hidden_states,注意与卷积网络不同,ViT 的每个 patch 是不重叠的。假设输入为 224x224,patch 为 14x14,那么一张图片会生成 $N = \frac{HW}{P^2} = \frac{224 \times 224}{14 \times 14} = 256$ 个 hidden_states,每个 hidden_states 的维度为 768,所以最终的 hidden_states 的维度为 256x768。使用一个kernel 为 14x14 且 stride 为 14x14 的卷积实现,有关这个类型 conv 和 matmul 的相互转换,见 将 ViT 的第一个卷积层转为 MatMul,要求步长和卷积核相等。
- Position Embedding:这是一个可学习的位置编码,shape 为 1x256,与 patch 数量相同。Position Embedding 包括 1D 和 2D,图中展示的是 1D 的位置编码;如果换为 2D 位置编码,shape 为 1x16x16,总的 token 数量不变。在 ViT 的论文中,讨论了有关 1D 和 2D 位置编码的区别,结论是有位置编码的模型效果更好,但是1D和2D的影响不大。
- Learnable Embedding:一个额外的可学习嵌入,shape 为 1x768,在图中是第 0 个 token
ViT 使用的是 Encoder-Only 结构,经过每一层 Encoder 的 shape 不变,保持为 256x768。最后增加了一个 MLP Head 用于分类。
PS:huggingface 中的 siglip-so400m-patch14-384 的含义是:基于 So-400M 的 SigLip 模型,使用 patch 大小为 14 的 384x384 的图像作为输入。
minicpm-v 中的视觉编码

上图介绍了 minicpm-v 的模型结构,为了将视觉编码器加入到 LLM 中,minicpm-v 中有关视觉编码器的内容如下:
- Image Partition:一种保持输入图像宽高比的预处理方式,最大可能地保留输入图像的原生宽高比。图中展示了 8 中不同的切分模式,最后选择了 2x3 的切分方式,这样在切为小图之后,也能够减小图像宽高比的变化
- Slice Encoding:由于图像的宽高比不变,对于矩形图像,就需要改变默认的方形位置编码以适应这种变化,图中的 2D Positional Embedding Interpolation 代表了从方形到矩形的变化。因此 minicpm-v 将 1D 的位置编码($P_1\in \mathbb{R}^{Q\times l}$)改为了 2D($P_2 \in \mathbb{R}^{d\times d \times l}$)。其中,$Q$ 表示 patch 数量,$l$ 表示 hidden size,$d = \sqrt{Q}$ 表示单个维度上 patch 的数量。
- Shared Compression Layer:minicpm-v 单张图片只使用了 64 个 token,而 Llava 需要 256 个 token
- Spatial Schema:经过视觉编码器和 projector 之后,视觉特征就嵌入到了 LLM 空间中,只需要将图片占位符的嵌入替换为视觉编码器的输出,LLM 就拥有了图片识别能力。最后 LLM 见到的输入格式为:
<image><slice>*N\n<text>,如图中 LLM 前的一部分输入所示
Spatial Schema 中的替换伪代码如下:
1 | # 获取视觉编码器的输出 |
语音编码器
Whisper
Whisper 是一个基于 Transformer 的语音识别模型,llama.cpp 的作者还开开发过一个 whisper.cpp。whisper 的架构如下:

Whisper 用的是 Encoder-Decoder 架构,Encoder 用于提取语音特征,Decoder 用于生成文本。EncoderLayer 是 Self-Attention + FFN,DecoderLayer 是 Self-Attention + Cross-Attention + FFN,Cross-Attention 接受了来自 Encoder 提取的特征作为 KV,目前的文本作为 Q 来进行自回归生成。
其它模块还包括:2 个 Conv1D + GELU 提取语音特征,以及 encoder 使用的是固定的 sinusoidal 位置编码,decoder 使用的是 learnable 位置编码。
minicpm-o
语音编码器使用的是 whisper-encoder 架构,除了将语音转为频域信息外,语音 token 嵌入到 LLM 中的方式和 minicpm-v 相同,最终 LLM 的嵌入格式为:<image><slice>*N\n<audio>*N\n<text>。

上图展示了 minicpm-o 的一个 demo 架构图,即可以实现:使用语音对视频流进行提问,生成回复后,使用语音回答。同时,这都是端到端实现的。
这张图上最重要的一个名称是 OTDM,全称 Omni-modality Time Division Multiplexer,多模态时分复用。落到实践上,就是以 1s 为间隔读取视频流,并通过视觉和语音编码器送入到 LLM 中。如果这个时候有语音提问,那么中间一部分的视频就会被截断(omitted inputs),直到语音结束,才重新读取视频流。
这个图中 LLM 的作用有三个:1、接收多模态的输入,包括视觉、语音和文本;2、生成文本,作为下一步 TTS 模型的输入;3、生成音色嵌入 $H_0$,作为 TTS 模型的输入。
TTS
由于作为骨干网络的 LLM 并不具备语音生成功能,所以 minicpm-o 额外使用了一个 TTS 模型,用于生成语音,TTS 模型来源于 ChatTTS 项目。
落到模型上,使用的是一个基于自回归范式的 transformer 模型,其架构如下:
整个模型包括三个部分:LLAMA 模型、DVAE 解码器、Vocos 解码器。作用如下:
- LLAMA 模型用于接收文本和音色输入,并生成语音 ID,每个语音 ID 的 shape 为 $[1, 4]$,范围为 0~625
- DVAE 解码器用于将语音 ID 解码为梅尔普频域特征。每个语音 ID 代表了码本(codebook)中的一个下标,码本的形状为 $[625, 4]$,因此语音 ID 不能超过 625,当生成 625 的 id 时,语音生成结束
- Vocos 解码器用于将梅尔频谱解码为语音信号
LLAMA 生成的语音为 50Hz,即 50 个语音 ID 为 1s 的语音。DVAE 将 50Hz 的语音解码为 100Hz 的梅尔频谱,Vocos 将梅尔频谱解码为语音信号。
流式生成
在文本对话过程中,模型每生成 1 个 token,用户都可以感知到字符出现。但是如果等到 LLM 生成所有的 token 之后,再生成语音,那么第一个语音生成速度(类似于 llama.cpp 中的 TTFT)会非常长,影响用户体验。因此,minicpm-o 增加了对流式生成支持,用户可以实时获取模型生成的语音。流式生成最重要的是 prefill 和 decode 的交替进行,在 minicpm-o 中,每次 prefill 25 个文本 token,decode 50 个语音 ID,同时 Audio Decoder 持有中间的 KV 缓存。
官方给出的流式生成 mask 如下:
| 图片 | 描述 |
|---|---|
 |
非流式生成时的 attention mask,非常标准的 casual mask,每个 token 只能看到自己以及之前的 token。 |
 |
流式生成的 attention mask 与上图有明显的差异点:① prefill 和 decode 之间有一段空隙,这是为 LLM 生成的文本而预留的,当有新的文本产生时,插入到 prefill text 中来;② decode 时只能看到已经生成的文本,而不能看到所有文本,例如 Audio15 不能看到还没有生成的 Text4~10 |
