ViT 卷积层
为了将输入的图片转为 patch,然后送入到 Transformer 中,ViT 第一个卷积的步长和卷积核大小是相等的,都是 16。如下图所示,
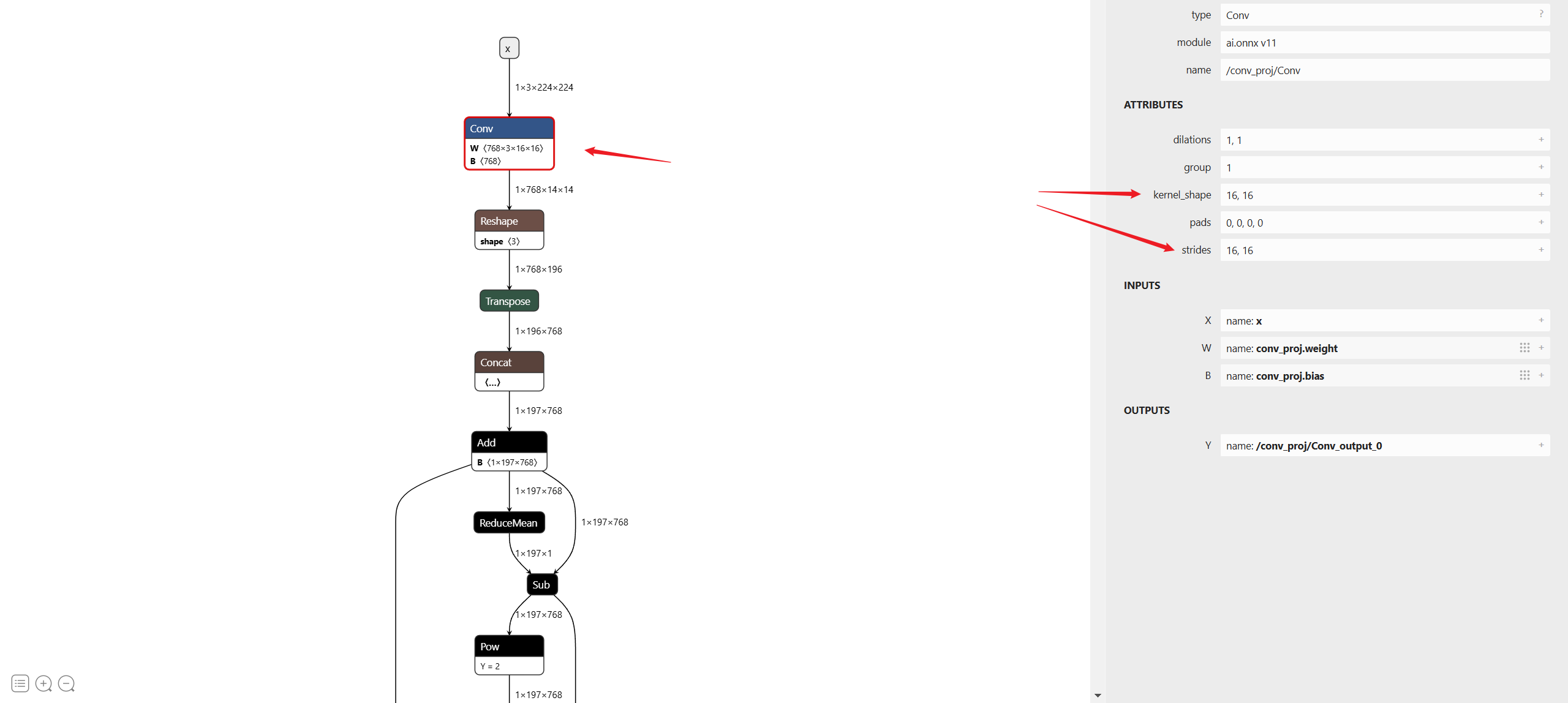
某些框架可能不支持这么大的 Conv 步长,导致无法转换相应模型。
MatMul
卷积可以使用 im2col 加 matmul 来实现,但是由于 im2col 可能效率不高,所以一般不使用这个方式。
不过我们注意到 ViT 第一个卷积层里的步长和卷积核大小是相等的,所以我们可以用 reshape + transpose 来实现 im2col。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def conv2d_to_matmul(inputs, kernel, stride, padding, bias):
assert stride == kernel.shape[2]
assert stride == kernel.shape[3]
assert padding == 0
output_h = (inputs.shape[2] - kernel.shape[2]) // stride + 1
output_w = (inputs.shape[3] - kernel.shape[3]) // stride + 1
reshaped_image = inputs.reshape(
inputs.shape[0], inputs.shape[1], output_h, stride, output_w, stride
)
input_vector = reshaped_image.permute(0, 2, 4, 1, 3, 5).reshape(
inputs.shape[0] * output_h * output_w, -1
)
kernel_vector = kernel.reshape(kernel.shape[0], -1).permtue(1, 0)
output = input_vector @ kernel_vector + bias
output = (
output.reshape(inputs.shape[0], output_h, output_w, -1)
.permute(0, 3, 1, 2)
.contiguous()
)
return output
|
测试结果如下,对比了使用 conv2d_to_matmul 和 F.conv2d 的结果,误差在 1e-4 左右,还能接受。(实际上不应该有误差,因为数学上是等价的)
1
2
3
| -> % python test.py
Difference sum between custom and PyTorch conv2d: 1.746861457824707
min: 0.0, max: 0.0001373291015625
|
