llama2
LLaMa2
Transformer Introduction
Architecture
transformer 最主要的结构就是这张图:
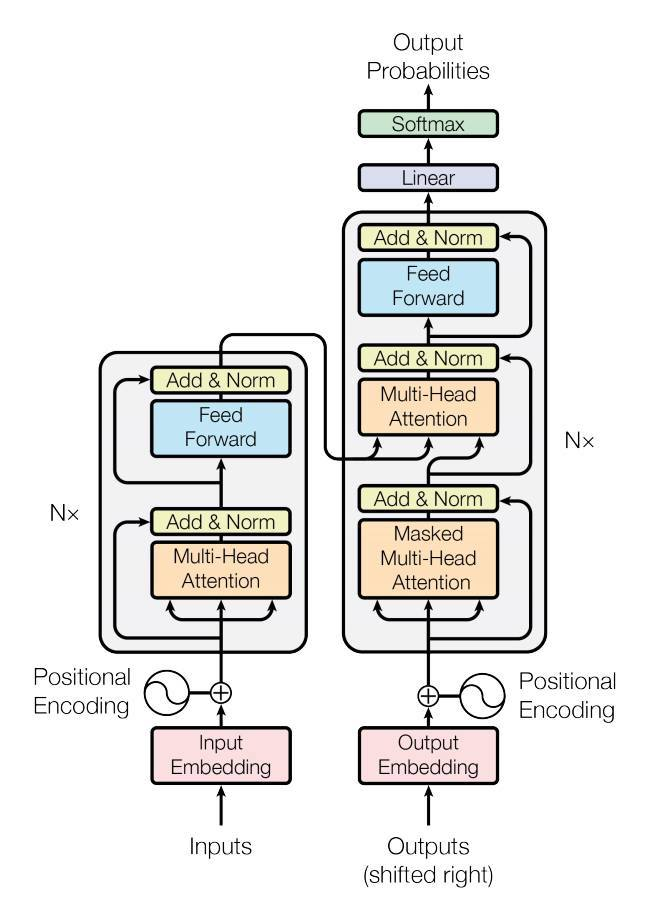
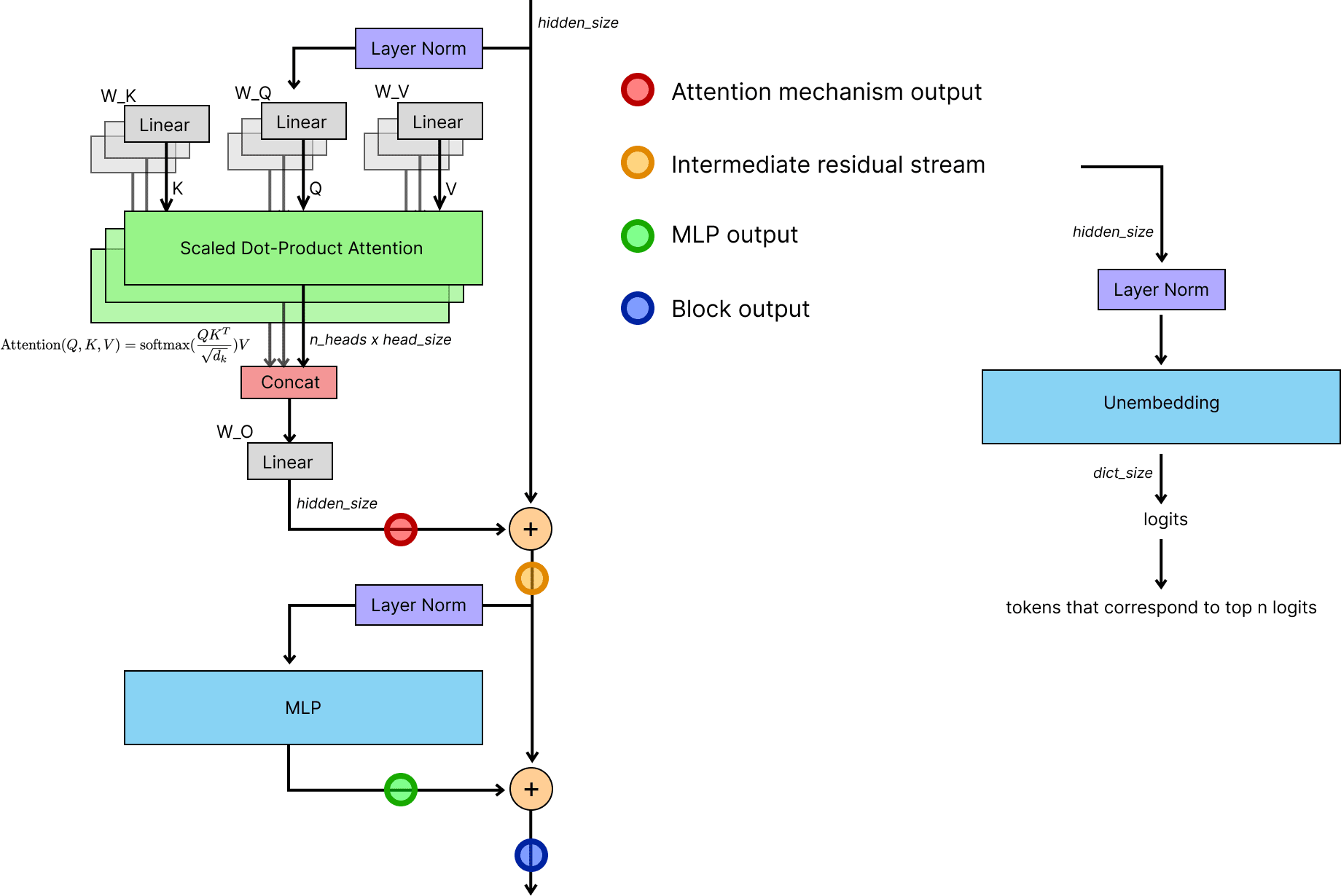
在纯 Encoder 或者纯 Decoder 的架构中,会变成只有左边的 transformer block 的结构,但是区别在于 Multi-Head Attention 是否存在 mask。Encoder-only 架构为了获取每一个 token 的完整上下文,因此没有对应的 mask;Decoder-only 架构为了让每一个 token 只能注意到它前面的 token,因此会存在一个从前往后的 mask,即生成的 $QK^T$ 矩阵(shape 为 $n_{tokens} \times n_{tokens}$)是一个下三角阵。
llama2 的 QK^T 矩阵注意力输出,Decoder 架构,因此是一个下三角阵
Encoder-Decoder
Transformer-based Encoder-Decoder Models
Transformer 是 Encoder-Decoder 结构的一种,这是为了解决在 NLP 中输入和输出长度不相同的问题,包括总结文本、生成新的文本。此前的 GRU 存在几个问题:1、Encoder 过长,会遗忘输入信息;2、Encoder 无法并行。(注意:Decoder 也无法并行,但是这是能够接受的,因为不知道输出的长度,因此只能每次输出一个 token)
为了一次 Encoder 推理捕获到全部的输入信息,transformer 将输入拼接起来,使用矩阵乘获取每个 token 之间的关系,然后通过 softmax 层变为系数矩阵,与输出的 V 矩阵相乘,得到了自注意力的输出。(为啥之前的 GRU 没有想到把所有的数据拼接,一次推理就能更新到最后的隐藏层的输出)
虽然预测推理时 Decoder 不能并行,但是训练时由于输出长度是已知的,所以使用了 Masked MHA 来进行并行化的训练。
输入和输出的 shape:$(N, \ N_{heads}, \ T, \ N_{embedding-size})$,$T$ 表示 time step,即输入 token 的数量;在 GPT 中,$T$ 随着输出不断变长。
注意:无论是 Encoder 还是 Decoder,它们输出的长度都是跟输入的长度是一样长的;在 Bert 中,输入是 masked sentence,输出是 reverse masked sentence,即对于被 mask 的单词的预测;在 GPT 中,它是一个生成任务,因此是通过不断地将输出拼接到输入中直到 token 为 EOS(End-Of-Sentence),由于输出和输入等长,因此输入是 $(BOS, x_1,x_2, \dots, x_{n-1})$,输出是 $(x_1,x_2,\cdots,x_n)$,最后一个 tensor 为当前输出的 token 的 embedding,通过 de-embedding 和 argmax 即可得到输出 token 的 id。
GPT
GPT 是 Decoder-only 的架构,用于生成式任务。如果我们没有任何的输入和 Prompt,那么第一个 token 为 BOS(Begin-Of-Sentence)。
在 PyTorch 中,由于支持变长输入,所以输入的生成应该是如下形式:
- BPE 序列化 Prompt 成 Embedding,与 Positional Encoding 相加,得到初始输入
- 如果没有 prompt,使用 BOS
- 每次输入得到相同长度的输出,取最后一个 step 的 tensor 为输出 token 的 embedding
Llama2.c
LLama2
llama2 对于 prompt 的处理
llama2 保持 transformer 架构的基本模式,即通过堆叠 tranformer block 来使得模型变深;与 CV 模型不同的是,CV 模型由于卷积模块的增加,feature map 会缩小,通道数会增加,因此不同 size 和 channel 的 block 不相同;但是 transformer block 是完全相同的,同一个类型的 block 从头用到尾,这也是输入和输出 shape 相同的原因。
llama2 的 transformer block 如下:
由于 transformer 都是这种结构堆叠而成,因此许多推理框架都把结构硬编码放到代码中,包括下面的 LLama2.c。原始的 transformer 中间没有 Rotary Positional Encoding,这是 2021 年的 RoFormer 提出的,具体可参考 Transformer升级之路:2、博采众长的旋转式位置编码 。
llama2.c
https://github.com/karpathy/llama2.c
llama2.c 根据上面的 llama2 的 transformer 的结构搭建了一个 transformer 的推理框架。主要介绍比较重要的几个模块。
BPE Encoding
部分分词法,能够得到英语中前后缀和词根,学习更多的数据。
算法如下:
- 将句子拆分成字母,字母变为“子词”
- 合并其中两个相邻的子词成为一个新的子词,新子词的得分必须是最高的
- 不断迭代第二步,直到没有新的子词生成,即两个相邻子词生成的子词无法在词汇表中找到
Prompt
prompt 可以理解为预先输入的一些单词,它们先走了一遍网络,初始化了权重,因此后面的输出才会根据 prompt 的提示输出。
RMSNorm
公式如下:
$$
X^\prime = W \cdot \frac{X}{(\sum_{i=1}^{n} X_i^2) / n}
$$
FFN
公式如下:
$$
X^\prime = W_2 \left ( (W_3 X) \cdot \text{SiLU} (W_1 X) \right )
$$
其中 $\text{SiLU}$ 函数如下:
$$
\text{SiLU}(x) = x \cdot \sigma(x) = \frac{x}{1 + \exp(-x)}
$$
KV Cache
由于 Decoder 每次推理生成一个 token,直到 token 为 EOS。每次推理得到的一个 token 会被视为新的输入再次执行推理,得到下一个 token。因此,之前生成的 Key 和 Value 矩阵可以保留下来,不需要再一次生成所有 token。
考虑到自注意力的公式为:
$$
\begin{align}
Q &= W_q X \
K &= W_k X \
V &= W_v X \
\text{Attn}(Q, K, V) &= Softmax \left ( \frac{QK^T}{\sqrt{n_{dim}}} \right )V
\end{align}
$$
假设有一行新的输入 $X_n$,经过投影后变为 $Q$ 的一行新的输入,经过自注意力后的输出与 $Q$ 的其它行无关,但是需要完整的 $K$ 和 $V$ 矩阵,因此我们需要 KV Cache。新的一行 KV Cache 就是新的输入 $X_n$ 经过投影之后的结果。