MNN 自定义算子,以 AnyNet 为例
1. 介绍
本文主要介绍如何在 MNN 中添加自定义算子,以 AnyNet 为例。AnyNet 添加了一个自定义算子,虽然可以用 pytorch 表达,并且导出 ONNX 和 MNN,但是节点过多,可视化工具无法很好的展示,因此本文尝试将 AnyNet 中的自定义算子添加到 MNN 中。
自定义 MNN 算子需要先将 pytorch 计算逻辑导出成 ONNX 节点,并且由 MNN 来解释。这需要首先将 pytorch 计算包装成 torch.autograd.Function,然后通过 torch.onnx.export 导出 ONNX 节点。然后通过 MNN 的 MNN::OpConverter 来解释 ONNX 节点。
2. AnyNet

AnyNet 自定义了一个 SPNet 算子,并且使用 CUDA 实现了这个算子。SPN的结构,分为两种,分别是单路连接和三路连接:
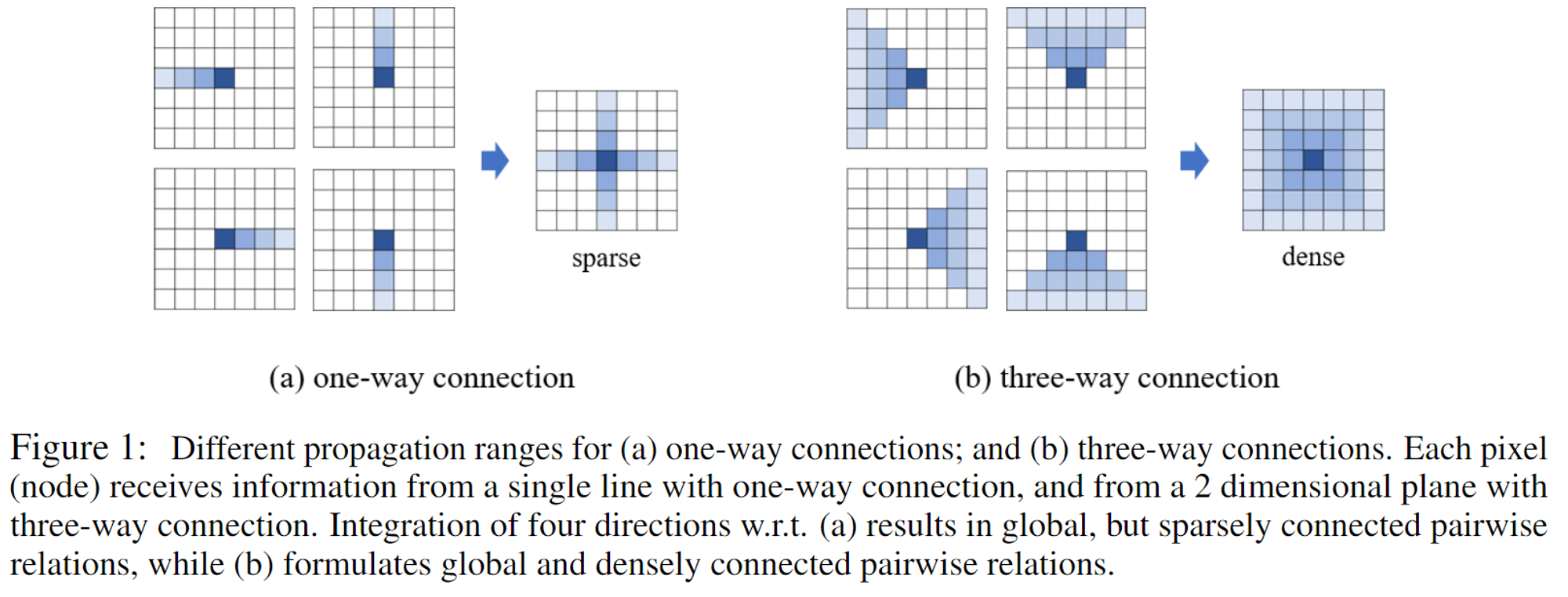
实际上就是通过一个权重矩阵,上一个点迭代地给下一个点权重,对于单路连接和三路连接,有:
$$
\begin{align}
h_{k,t} &= (1 - p_{k,t}) \cdot x_{k,t} + p_{k,t} \cdot h_{k,t-1} \
h_{k,t} &= (1 - \sum_{k \in \mathbb{N}} p_{k,t}) x_{k,t} + \sum_{k \in \mathbb{N}}p_{k,t} h_{k,t-1}
\end{align}
$$
$p$是权重,$x$是当前点的值,$h$是传播后的值,$k$是行索引,$t$是列索引。AnyNet使用的是三路连接中的left to right,重复传播(recurrent propagation)要求下一个点的值依赖于上三个点(也就是左边三个点)的值。
下面是 CUDA 实现和 pytorch 实现。
1 |
|
1 | class GateRecurrent(nn.Module): |
3. 自定义 ONNX 算子
待续
