Cosplay 视频转图片 1. 介绍 有很多时候 Cosplay 视频里的 Cosplayer 只有几个相同的画面,但是他们还是发出了一个短视频用于展示。我们想要把相同的画面剔除,对每个不同的画面保留一张图片。从信息论的角度来看,大部分 Cosplay 短视频的信息熵很低,只有几张图片是有意义的。这个项目就是为了尝试提取这些有意义的图片。
调研之后发现这是一个类似视频总结(Video Summarization)的问题。视频总结是一个很大的研究领域,有很多工作。这个项目只是一个简单的尝试,不会涉及到很多复杂的技术。
2. 方法 受到 2401.04962v1 的启发,这个问题主要针对的是视频中的重复帧。我们可以通过计算每一帧的特征向量,然后通过聚类算法来找到相似的帧。这个项目使用了 K-means 算法来聚类。
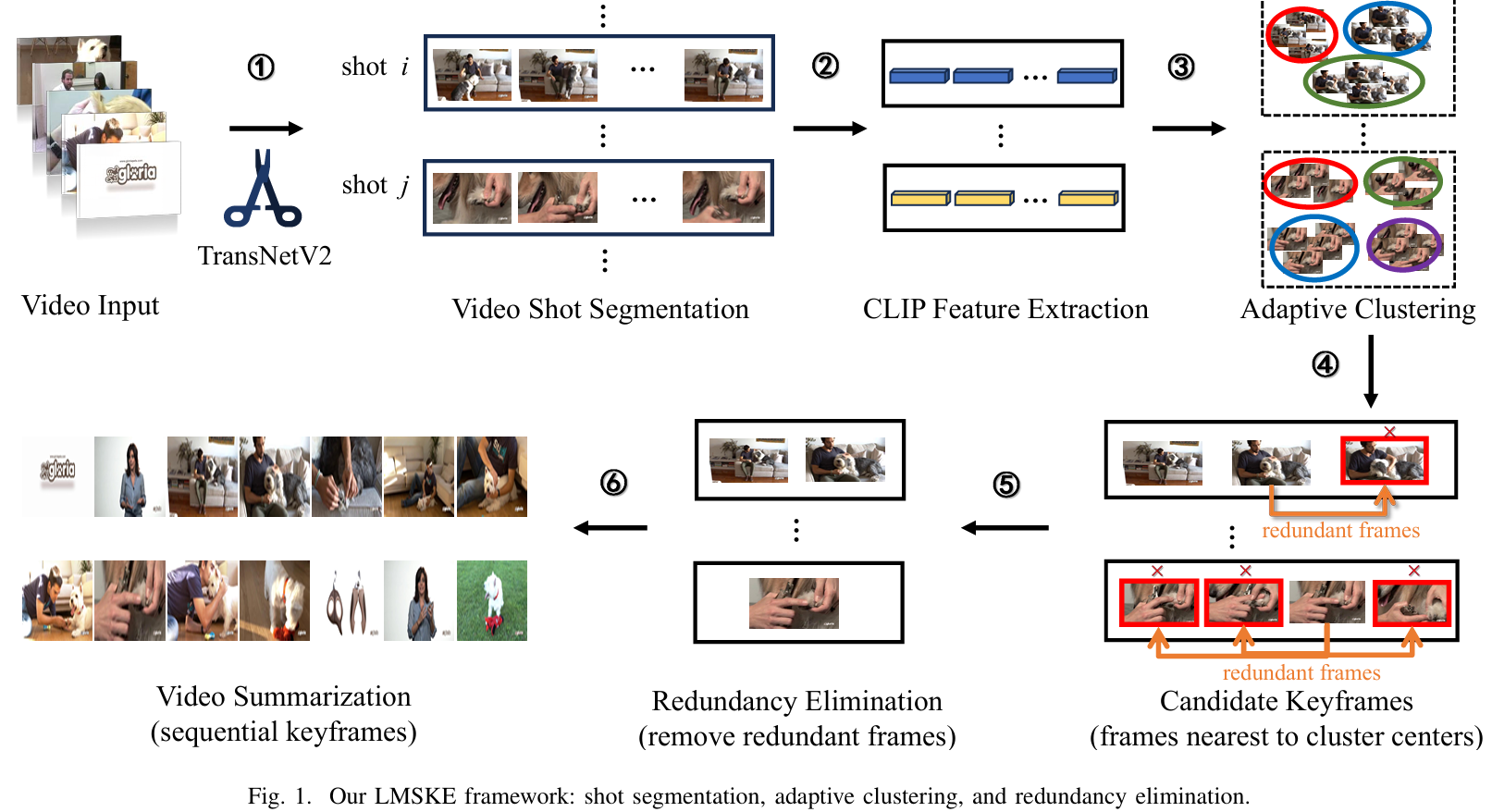
2401.04962v1 的架构图如下:
这个工作将视频总结(Video summarization)工作分为了三个步骤:
使用 TransNetV2 对视频进行分割,得到单个短视频(shot),使用 CLIP 对每个短视频每一帧进行特征提取,得到每一个视频的特征描述 $F_i = (f_{s_i}, f_{e_i})$ ,其中 $s_i$ 和 $e_i$ 表示第 $i$ 个视频的开始时间点和结束时间点。
自适应聚类算法(adaptive clustering)。通过自监督的聚类算法得到短视频关键帧,该工作使用的是 KMeans。为了得到最佳的聚类个数,作者提出了自适应聚类算法。(没有看完 )
重复帧消除(redundancy elimination)。消除无信息帧(如纯色图片)或者相似帧。使用 SSIM 矩阵取出相似帧。
为什么用 CLIP?ViT 的输出是一个 $197 \times 768$ 矩阵,CLIP 输出一个 $1 \times 512$ 矩阵,更紧凑,下游任务更友好。其它视频总结的工作也使用 CLIP 作为骨干网络提取特征。
迁移到本文提到的任务中,暂时不需要视频分割,只需要提取特征并聚类得到图像即可。代码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 import cv2import numpy as npfrom PIL import Imagefrom sklearn.cluster import KMeansimport torchfrom tqdm import tqdmimport transformersfrom transformers import AutoProcessor, CLIPVisionModelWithProjectiondef extract_clip_feature_for_video (video_path ): """ 使用 transformers 中的 CLIP 视觉模型提取视频中每一帧的特征 """ model = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-base-patch32" ) processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32" ) cap = cv2.VideoCapture(video_path) if not cap.isOpened(): print ("Error: Could not open video." ) return None i = 0 features = [] while True : start = cv2.getTickCount() ret, frame = cap.read() if not ret: break frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) image = Image.fromarray(frame) inputs = processor(images=image, return_tensors="pt" ) with torch.no_grad(): outputs = model(**inputs) image_embeds = outputs.image_embeds features.append(image_embeds.cpu().numpy().squeeze()) end = cv2.getTickCount() elapsed = (end - start) / cv2.getTickFrequency() i += 1 print (f"Processed {i} /{frame_count} frames. cost {elapsed} " , end="\r" ) cap.release() return features def feature_clustering (features ): """ 对特征进行聚类 """ features = np.array(features) kmeans = KMeans(n_clusters=10 , random_state=0 ).fit(features) labels = kmeans.labels_ centers = kmeans.cluster_centers_ indices = [] for center in centers: index = np.argmin(np.linalg.norm(features - center, axis=1 )) indices.append(index) return indices def save_frames (video_path, indices ): """ 保存视频中特定帧的图片 """ cap = cv2.VideoCapture(video_path) if not cap.isOpened(): print ("Error: Could not open video." ) return None count = 0 while True : ret, frame = cap.read() if not ret: break if count in indices: cv2.imwrite(f"frame_{count} .jpg" , frame) count += 1 cap.release() if __name__ == '__main__' : video_path = "“父 亲 大 人” [BV1VM4m1Z7ug].mp4" features = extract_clip_feature_for_video(video_path) print (features[0 ].shape) indices = feature_clustering(features) print (indices) save_frames(video_path, indices) print ("Done." )
KMeans 聚类中心的超参数设为了 10,这个值可以根据实际情况调整。
3. TODO
UniVTG 是一个视频总结的工作,可以参考。有视频总结、时间段查找、高光片段提取等功能。低质量帧的检测和剔除。
自适应聚类大小的确定。