课件截图 容器
list
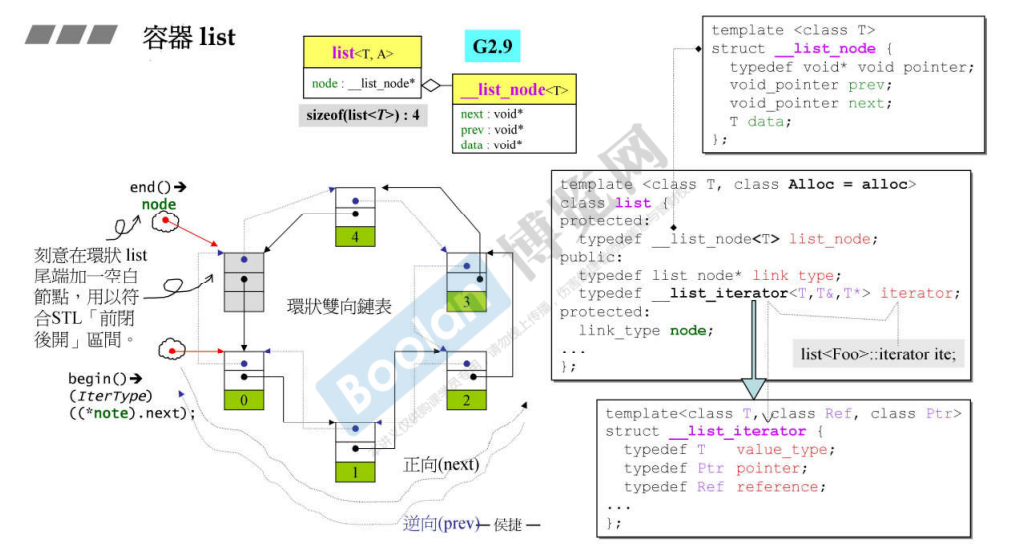
list 是一个双向链表,如果需要写一个 MyList ,那就可以参考 list 的写法。
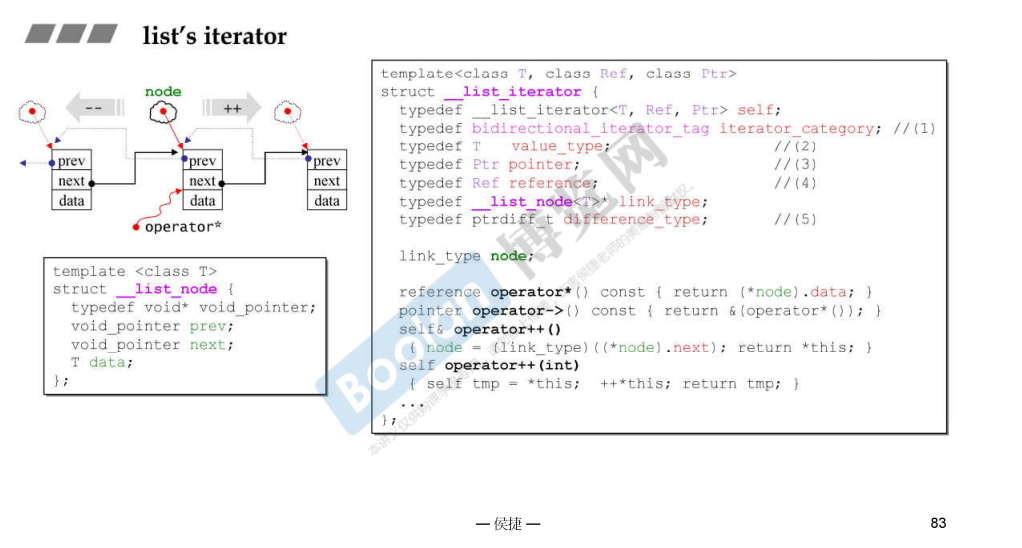
注意到这里的 bidirectional_iterator_tag ,这表明 list 的迭代器是一个双向迭代器,只支持图中展示的四个操作。但是 vector 的迭代器是 RandomAcessIterator ,可以支持随机访问,因此能够使用 std::sort ,而不需要本身带有一个 sort 函数。
在之前的黑马程序员里也讲过这个编译器优化案例。
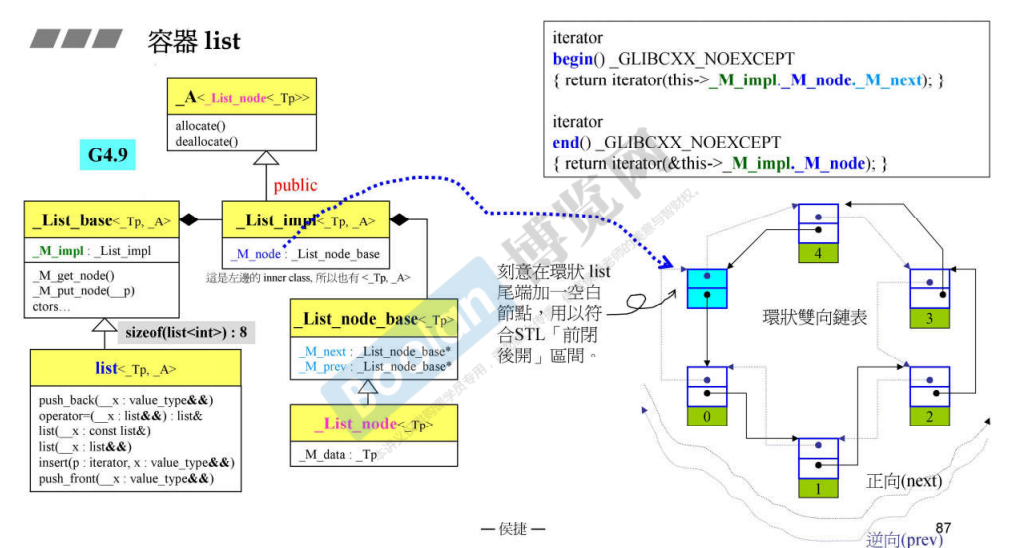
list 的迭代器在 2.9 和 4.9 中存在一定的不同,2.9 中的指针类型和引用类型都是不固定的,可以任意指定,但是 4.9 中的都与数据成员 _Tp 一致。同时,指针类型也通过继承实现了自带的 next 和 prev 。(可以用于以后的实现)
但是目前 MSVC 的实现并不一样,而是使用了一个 Node_Ptr ,其等于 typename pointer_traits<type-parameter-0-1>::template rebind<_List_node<_Value_type, _Voidptr>> 。(rebind 做 allocator)
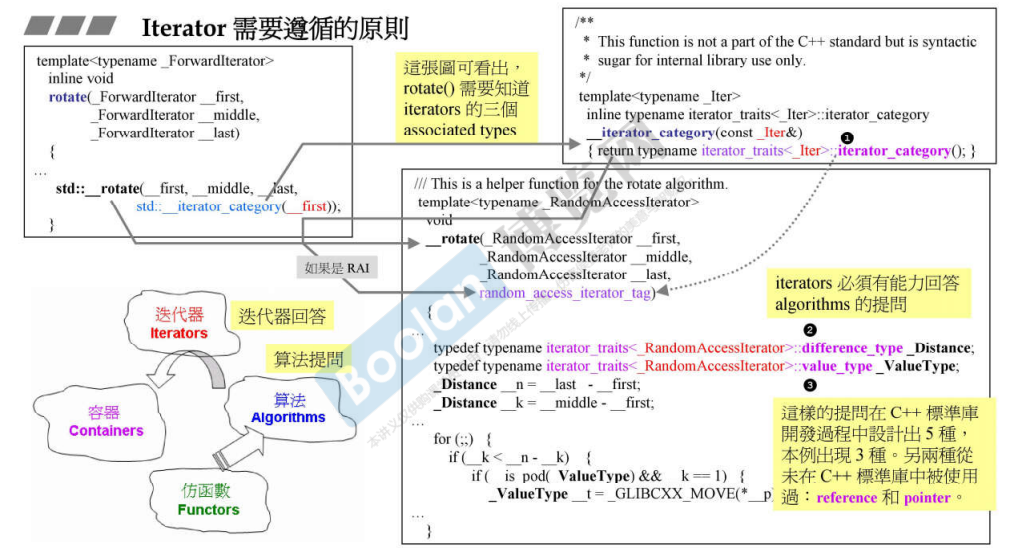
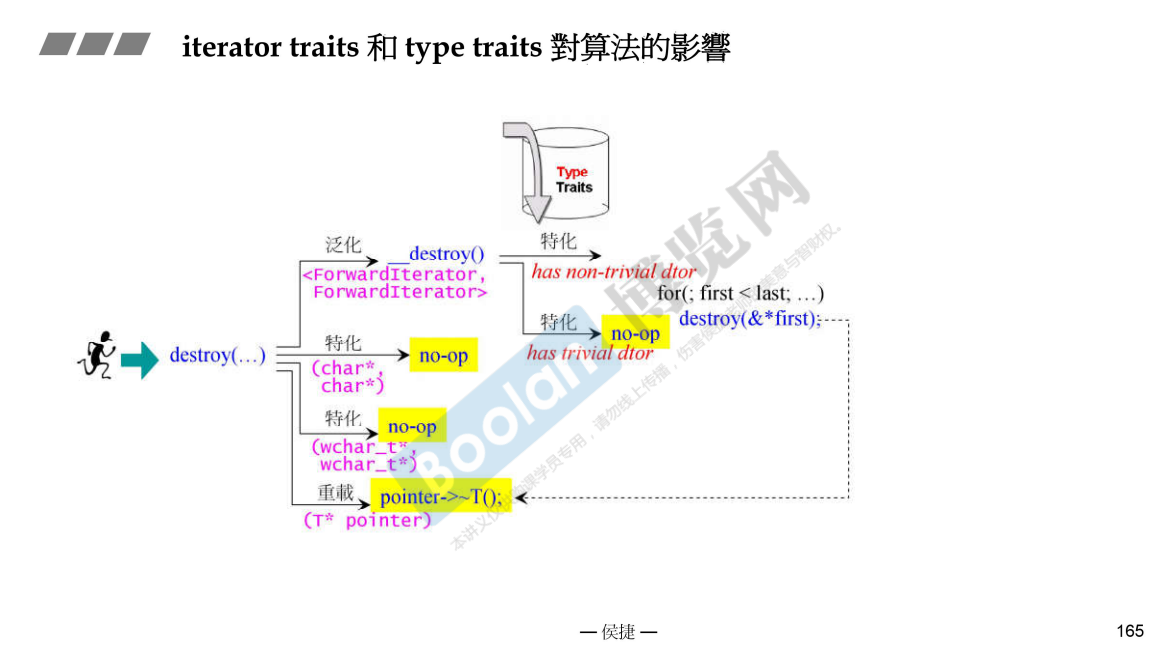
iterator traits
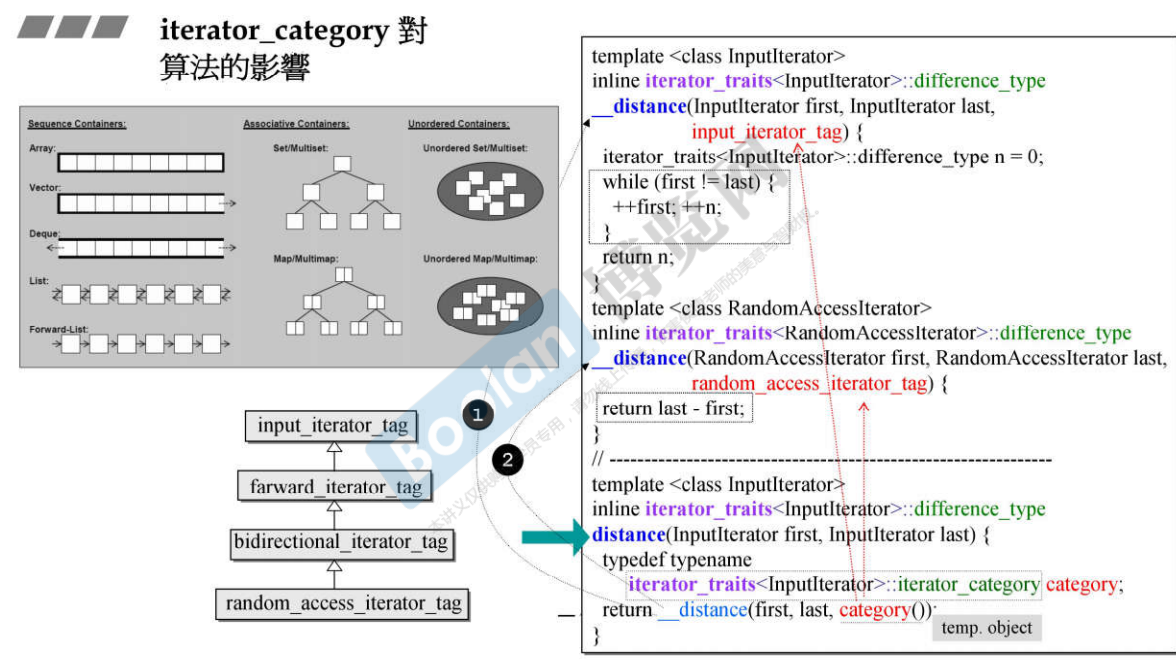
迭代器提供了五种 Type,都可以被算法访问。上面的 typename iterator_traits<_Iter>::iterator_category() 应该返回的是迭代器的类型(这应该是泛型编程中的内容 → TODO )
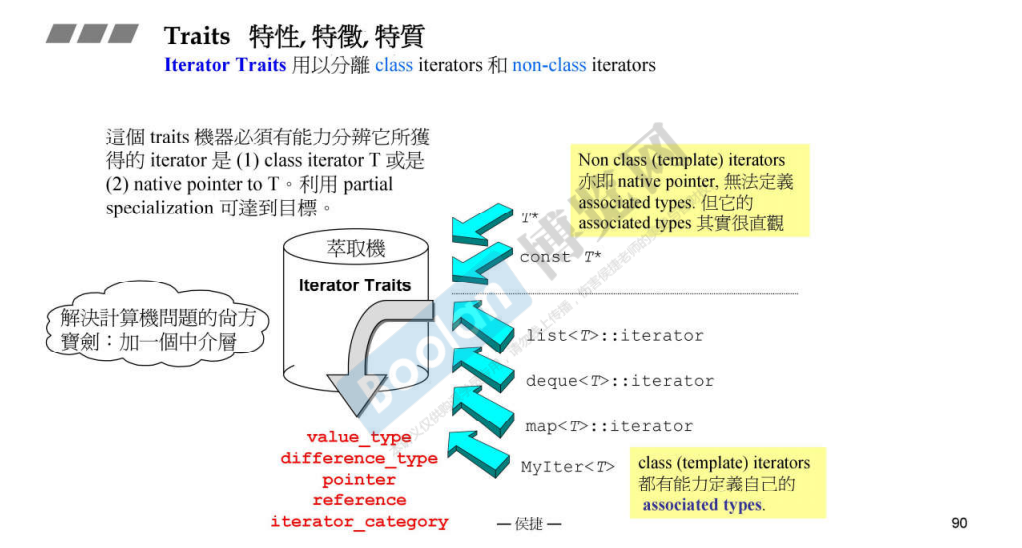
泛型编程中的 _Traits 是一种编程技巧,用来将模板参数和类型之间的联系抽象出来,以便实现更加灵活的编程。它实际上是一种类型提取技术,可以从类型中提取出一些其他的类型。比如,C++ 中的 iterator_traits 就可以用来提取迭代器的类型,std::sort 就可以根据迭代器的类型选择合适的排序算法。
下面是 MSVC 的代码,与上图的代码基本一致:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 template <class , class = void >struct _Iterator_traits_base {}; template <class _Iter >struct _Iterator_traits_base <_Iter, void_t <typename _Iter::iterator_category, typename _Iter::value_type, typename _Iter::difference_type, typename _Iter::pointer, typename _Iter::reference>> { using iterator_category = typename _Iter::iterator_category; using value_type = typename _Iter::value_type; using difference_type = typename _Iter::difference_type; using pointer = typename _Iter::pointer; using reference = typename _Iter::reference; }; template <class _Ty , bool = is_object_v<_Ty>>struct _Iterator_traits_pointer_base { using iterator_category = random_access_iterator_tag; using value_type = remove_cv_t <_Ty>; using difference_type = ptrdiff_t ; using pointer = _Ty*; using reference = _Ty&; }; template <class _Ty >struct _Iterator_traits_pointer_base <_Ty, false > {}; template <class _Iter >struct iterator_traits : _Iterator_traits_base<_Iter> {}; template <class _Ty >struct iterator_traits <_Ty*> : _Iterator_traits_pointer_base<_Ty> {}; #endif
iterator_traits 提供了迭代器和指针类型两种类型,指针类型进入到 _Iterator_traits_pointer_base ,迭代器类型进入到 _Iterator_traits_base 。
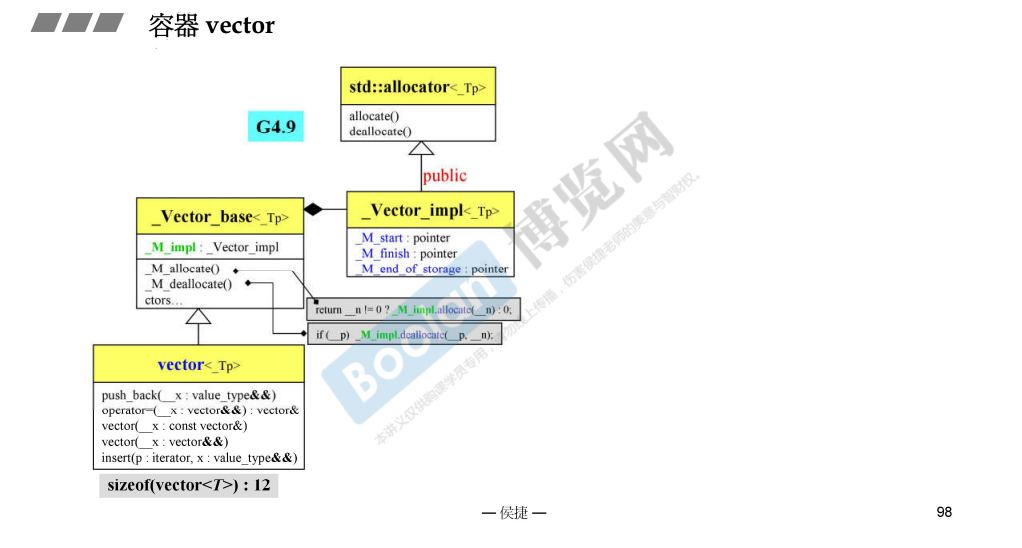
vector
vector 的简单的实现。
课件上的实现是直接扩大成两倍,然后拷贝源数据。MSVC 上的实现有所不同,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 template <class ... _Valty> _CONSTEXPR20 _Ty& _Emplace_one_at_back(_Valty&&... _Val) { auto & _My_data = _Mypair._Myval2; pointer& _Mylast = _My_data._Mylast; if (_Mylast != _My_data._Myend) { return _Emplace_back_with_unused_capacity(_STD forward<_Valty>(_Val)...); } return *_Emplace_reallocate(_Mylast, _STD forward<_Valty>(_Val)...); } template <class ... _Valty> _CONSTEXPR20 pointer _Emplace_reallocate(const pointer _Whereptr, _Valty&&... _Val) { _Alty& _Al = _Getal(); auto & _My_data = _Mypair._Myval2; pointer& _Myfirst = _My_data._Myfirst; pointer& _Mylast = _My_data._Mylast; _STL_INTERNAL_CHECK(_Mylast == _My_data._Myend); const auto _Whereoff = static_cast <size_type>(_Whereptr - _Myfirst); const auto _Oldsize = static_cast <size_type>(_Mylast - _Myfirst); if (_Oldsize == max_size ()) { _Xlength(); } const size_type _Newsize = _Oldsize + 1 ; const size_type _Newcapacity = _Calculate_growth(_Newsize); const pointer _Newvec = _Al.allocate (_Newcapacity); const pointer _Constructed_last = _Newvec + _Whereoff + 1 ; pointer _Constructed_first = _Constructed_last; _CATCH_ALL _Destroy_range(_Constructed_first, _Constructed_last, _Al); _Al.deallocate (_Newvec, _Newcapacity); _RERAISE; _CATCH_END _Change_array(_Newvec, _Newsize, _Newcapacity); return _Newvec + _Whereoff; } _CONSTEXPR20 size_type _Calculate_growth(const size_type _Newsize) const { const size_type _Oldcapacity = capacity (); const auto _Max = max_size (); if (_Oldcapacity > _Max - _Oldcapacity / 2 ) { return _Max; } const size_type _Geometric = _Oldcapacity + _Oldcapacity / 2 ; if (_Geometric < _Newsize) { return _Newsize; } return _Geometric; }
MSVC 上返回了一个 _Geometric 的大小,相当于每次增加 capacity 的一半 ,即 1 -> 2 -> 3 -> 4 -> 6 -> 9 -> 13 ,是符合之前黑马程序员的视频显示的结果的(**_NewSize + 1 就是为了防止大小为 1 的时候一直得到 0**)。
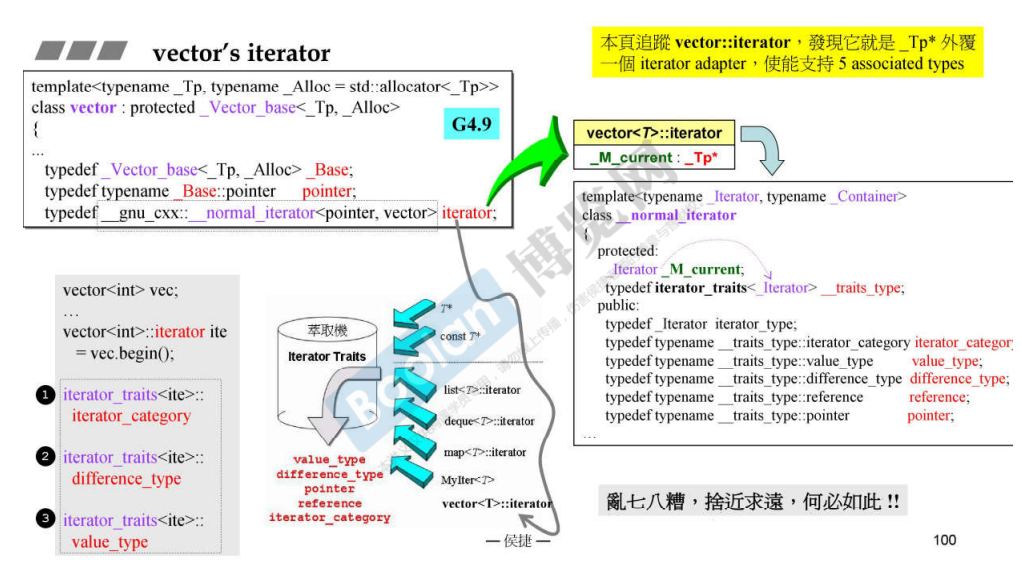
1 2 3 4 5 6 7 8 9 vector<int > v = {0 ,1 ,2 ,3 ,4 ,5 ,6 ,7 }; v.push_back (8 ); vector<int >::iterator::iterator_category c; vector<int >::iterator::difference_type t; vector<int >::iterator::value_type vt; struct random_access_iterator_tag : bidirectional_iterator_tag {};
iterator_category 就是在算法使用时根据不同的迭代器,调用不同的实现,所以这个类型只需要起到名称占位即可。
vector 的继承关系。
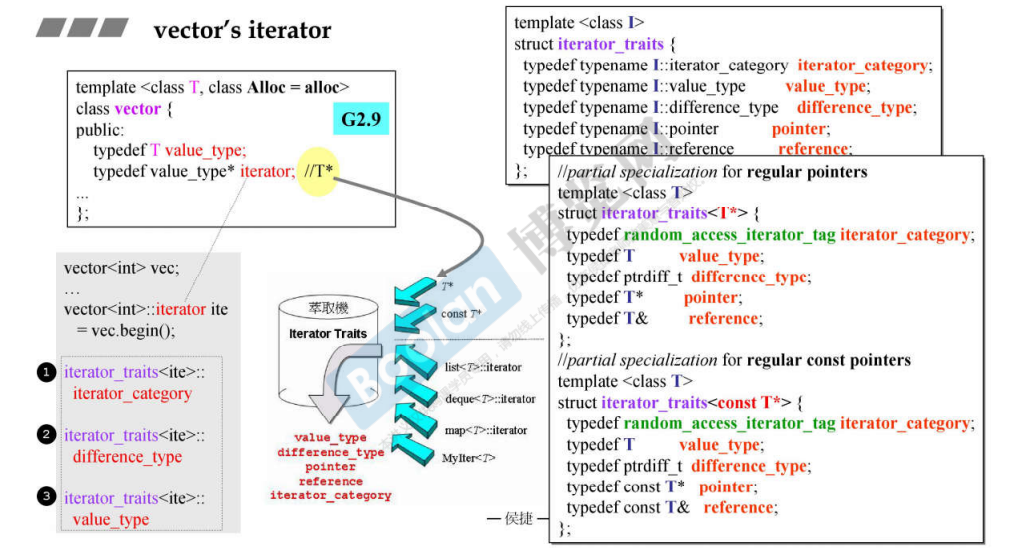
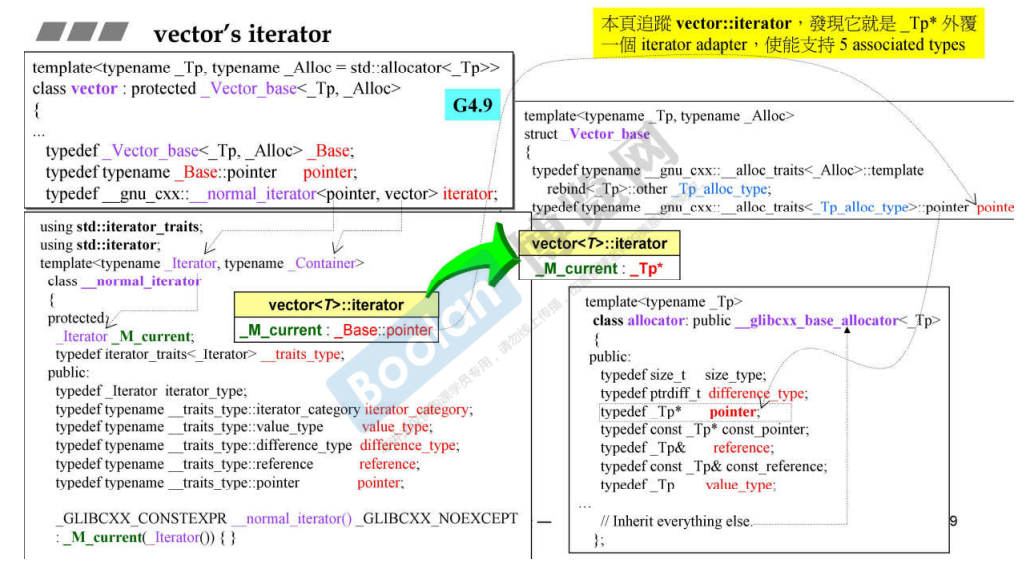
课件上的 vector 迭代器的实现,最终是基于指针的,迭代器的数据部分的 _M_current ,最终只是对指针 _Tp* 进行了包装。但是为什么要做一层额外的包装 ?
MSVC 的实现也是类似:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 template <class _Ty , class _Alloc = allocator<_Ty>>class vector { private : template <class > friend class _Vb_val; friend _Tidy_guard<vector>; using _Alty = _Rebind_alloc_t<_Alloc, _Ty>; using _Alty_traits = allocator_traits<_Alty>; public : static_assert (!_ENFORCE_MATCHING_ALLOCATORS || is_same_v<_Ty, typename _Alloc::value_type>, _MISMATCHED_ALLOCATOR_MESSAGE("vector<T, Allocator>" , "T" )); using value_type = _Ty; using allocator_type = _Alloc; using pointer = typename _Alty_traits::pointer; using const_pointer = typename _Alty_traits::const_pointer; using reference = _Ty&; using const_reference = const _Ty&; using size_type = typename _Alty_traits::size_type; using difference_type = typename _Alty_traits::difference_type; private : using _Scary_val = _Vector_val<conditional_t <_Is_simple_alloc_v<_Alty>, _Simple_types<_Ty>, _Vec_iter_types<_Ty, size_type, difference_type, pointer, const_pointer, _Ty&, const _Ty&>>>; public : using iterator = _Vector_iterator<_Scary_val>; using const_iterator = _Vector_const_iterator<_Scary_val>; using reverse_iterator = _STD reverse_iterator<iterator>; using const_reverse_iterator = _STD reverse_iterator<const_iterator>; template <class _Myvec >class _Vector_iterator : public _Vector_const_iterator<_Myvec> {public : using _Mybase = _Vector_const_iterator<_Myvec>; _STD_BEGIN template <class _Myvec >class _Vector_const_iterator : public _Iterator_base {public : using _Tptr = typename _Myvec::pointer; _Tptr _ptr;
最终的函数指针落到了 _Scary_val 上,这个类型是通过泛型编程得到的,即 is_same_v<> 判断类型是否是简单类型,然后决定使用是指针还是包装类型。
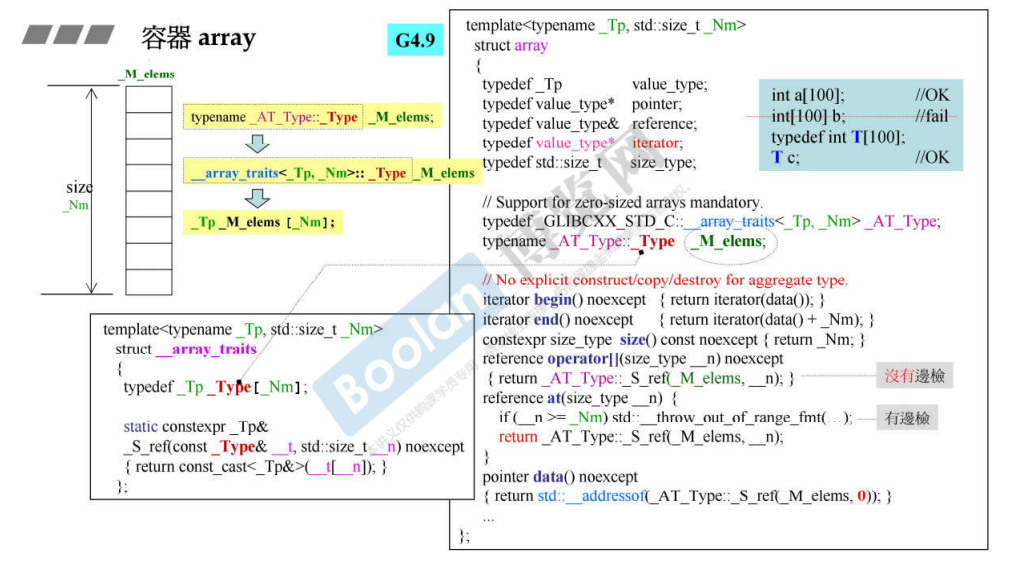
array
array 的实现跟普通的 C++ 数组一致,都是用的指针类型,如上面的 _M_instance 。MSVC 中也是一样的:
1 2 3 4 5 template <class _Ty , size_t _Size>class array { public : _Ty _Elems[_Size]; }
G4.9 的实现中有名称的定义。
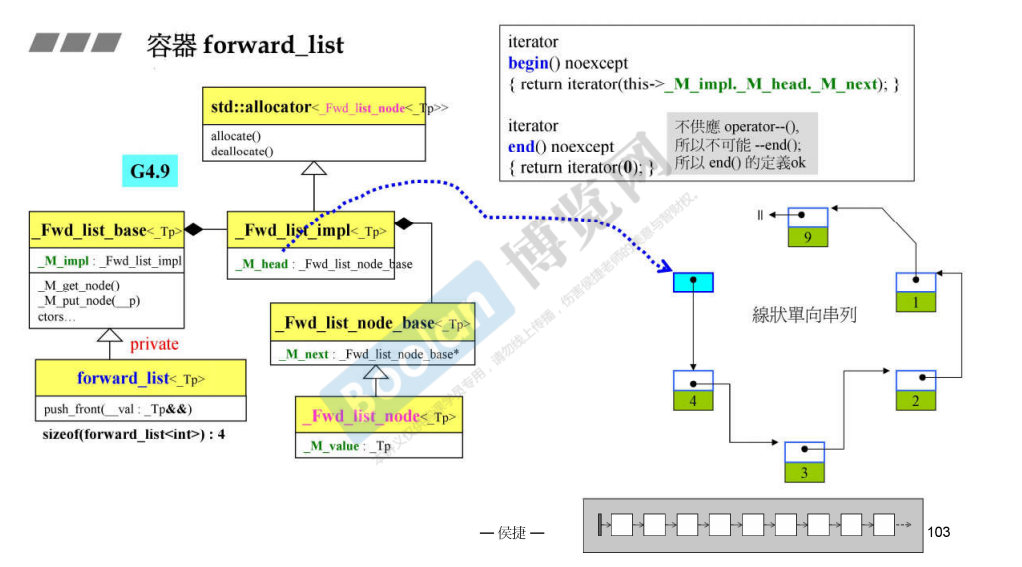
forward_list
单链表 forward_list 的实现,及其迭代器的实现。注意,end() 返回的是 0,也就是 NULL,所以当迭代器走到 NULL 的时候,也就等于走到了 end。因此,这样的定义是可行的。
MSVC 的实现也是一样的:
1 2 3 4 5 6 7 _NODISCARD iterator begin () noexcept { return iterator (_Mypair._Myval2._Myhead, _STD addressof (_Mypair._Myval2)); } _NODISCARD iterator end () noexcept { return iterator (nullptr , _STD addressof (_Mypair._Myval2)); }
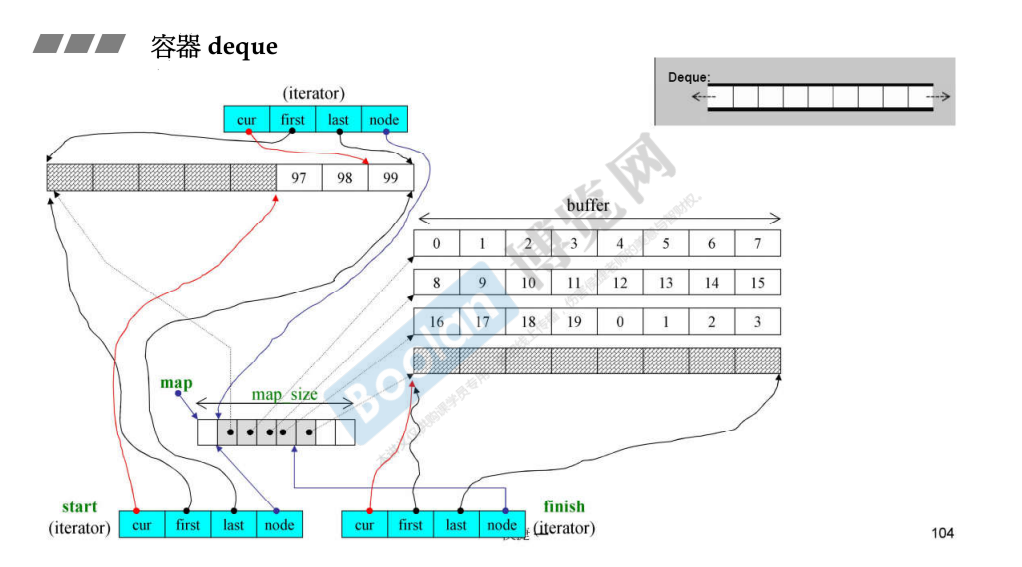
deque
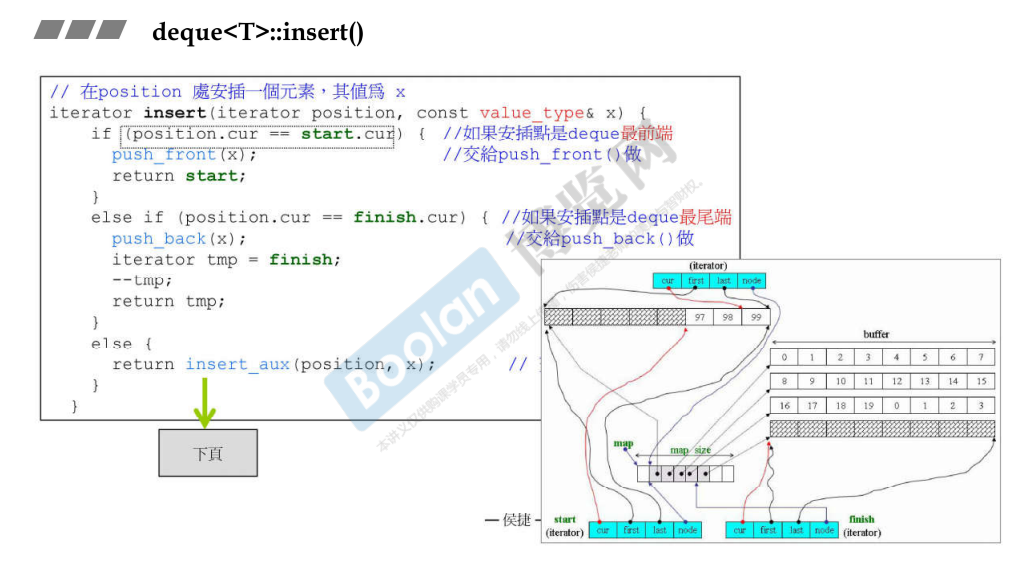
deque 的底层数据结构,图中的 iterator 构造表示迭代器的位置,deque 的迭代器有四个属性,分为块的开始和结束、当前指针、当前块的指针。因为这种结构存有缓冲区,所以能够以常数时间扩充。
如果缓冲区满了,是否也要像 vector 那样复制数据 ?
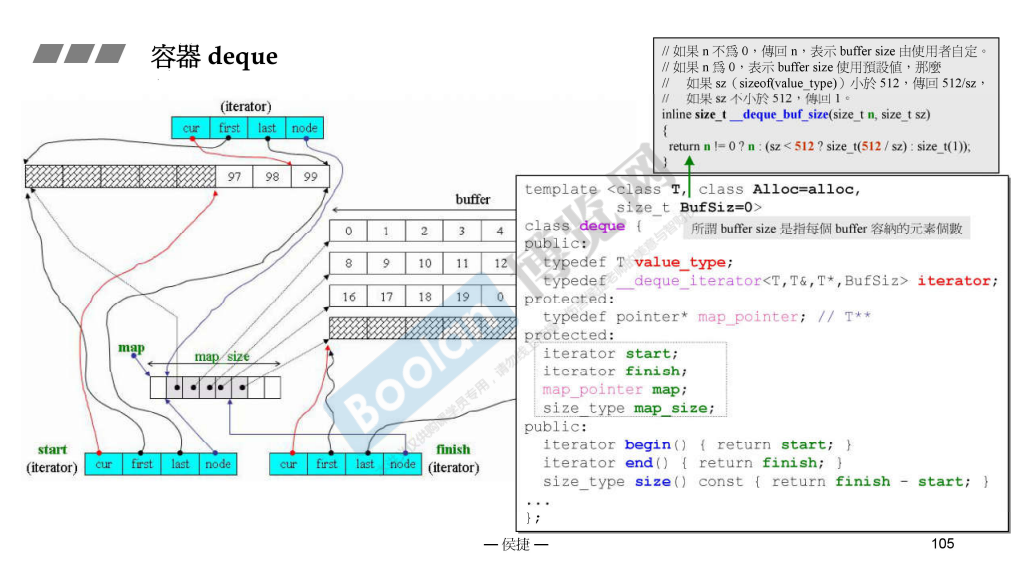
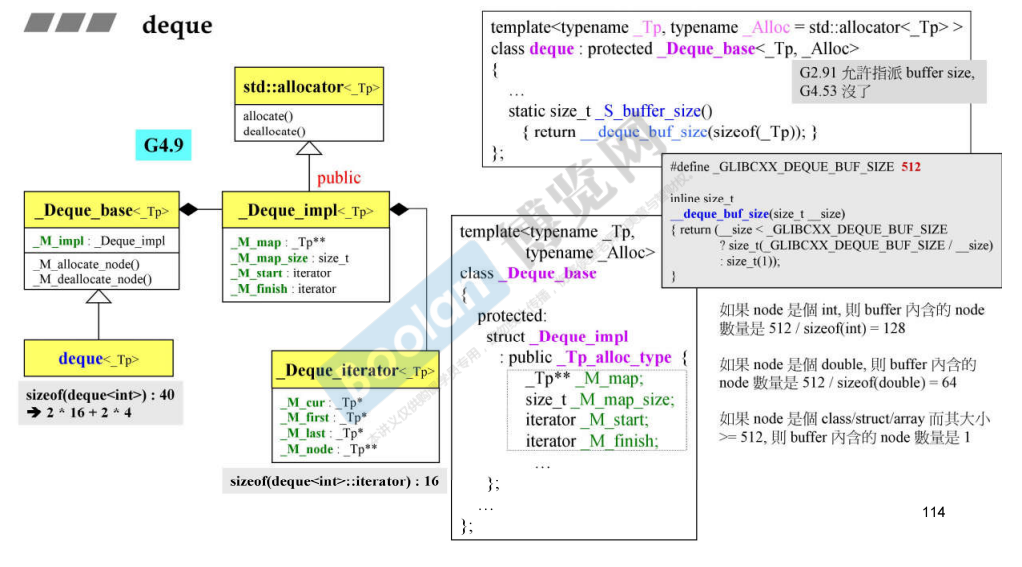
谈到了 buffersize 的大小的设定,MSVC 中同样是使用泛型得到的。路径如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <class _Ty , class _Alloc = allocator<_Ty>>class deque {private : using _Scary_val = _Deque_val<conditional_t <_Is_simple_alloc_v<_Alty>, _Deque_simple_types<_Ty>, _Deque_iter_types<_Ty, typename _Alty_traits::size_type, typename _Alty_traits::difference_type, typename _Alty_traits::pointer, typename _Alty_traits::const_pointer, _Ty&, const _Ty&, _Mapptr>>>; static constexpr int _Minimum_map_size = 8 ; static constexpr int _Block_size = _Scary_val::_Block_size; }; template <class _Val_types >class _Deque_val : public _Container_base12 {public : static constexpr int _Block_size = _Bytes <= 1 ? 16 : _Bytes <= 2 ? 8 : _Bytes <= 4 ? 4 : _Bytes <= 8 ? 2 : 1 ; };
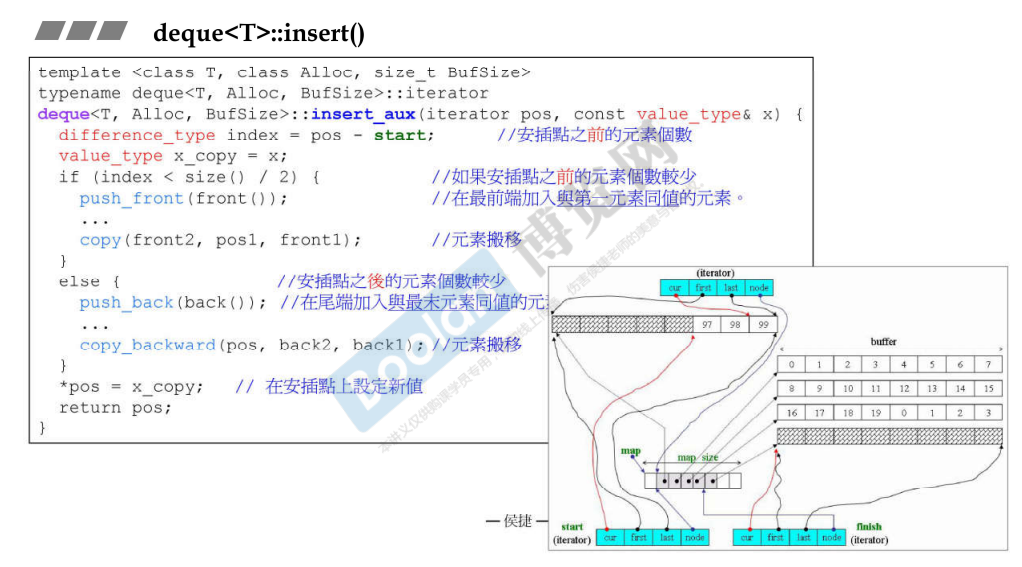
可以看到,deque 的插入跟 vector 是一样的,也需要复制元素
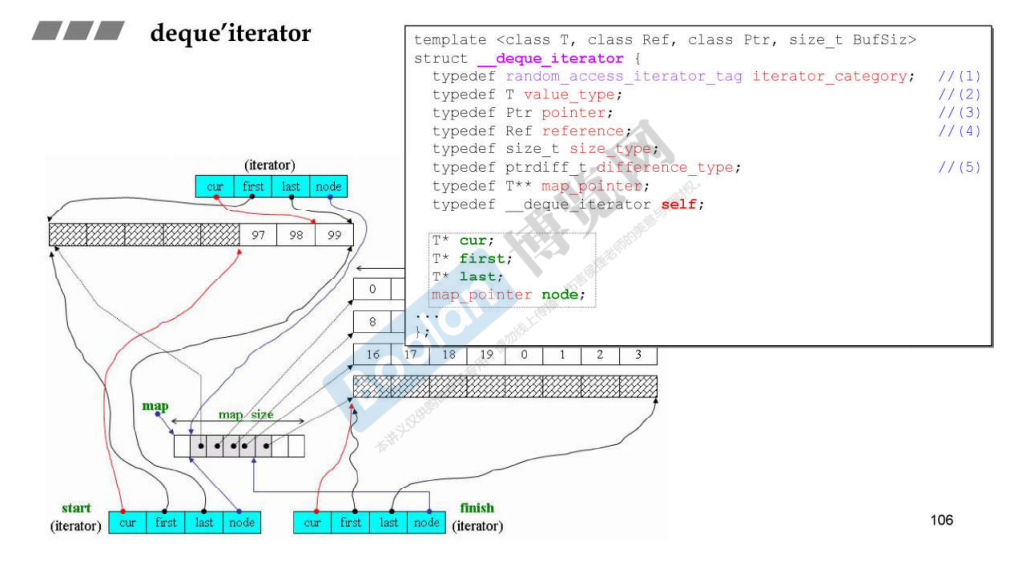
这部分是 deque 的迭代器是随机访问迭代器的关键。iter += 1 通过移动迭代器,如果在同一个块内,就迭代器,否则先移动块,然后再移动 offset。
first + (offset - *** 时已经切换好了块位置,first 指向的就是当前块的地址,所以只需要移动 node_offset 的距离即可。
因此,deque 能够使用数组索引符号进行访问。
从这张图上,我们还可以看出 difference_type 其实是两个指针之间的距离(或者是两个迭代器之间的距离),difference_type(buffer_size()) 就是将缓冲区大小的类型转换为 difference_type。
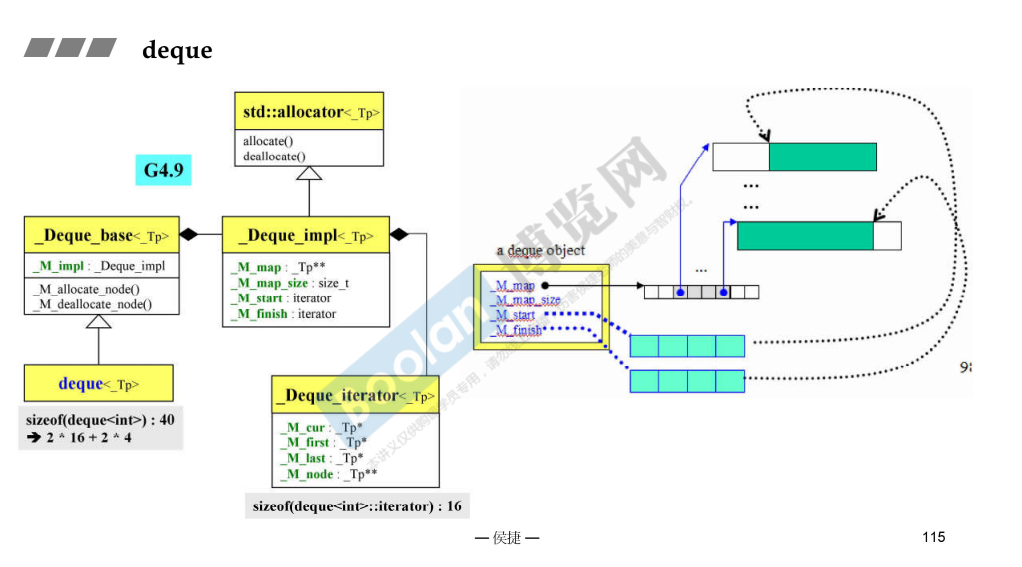
deque 的继承图。
说明了 deque 的类成员,及其数据结构
在 MSVC 里的 stack 的定义是:
1 2 template <class _Ty , class _Container = deque<_Ty>>class stack {}
默认选用了 deque 作为容器。
stack 和 queue 可以选择序列容器作为其数据结构,但是 vector 因为没有 pop_front 方法,所以不建议作为 queue 的数据结构。
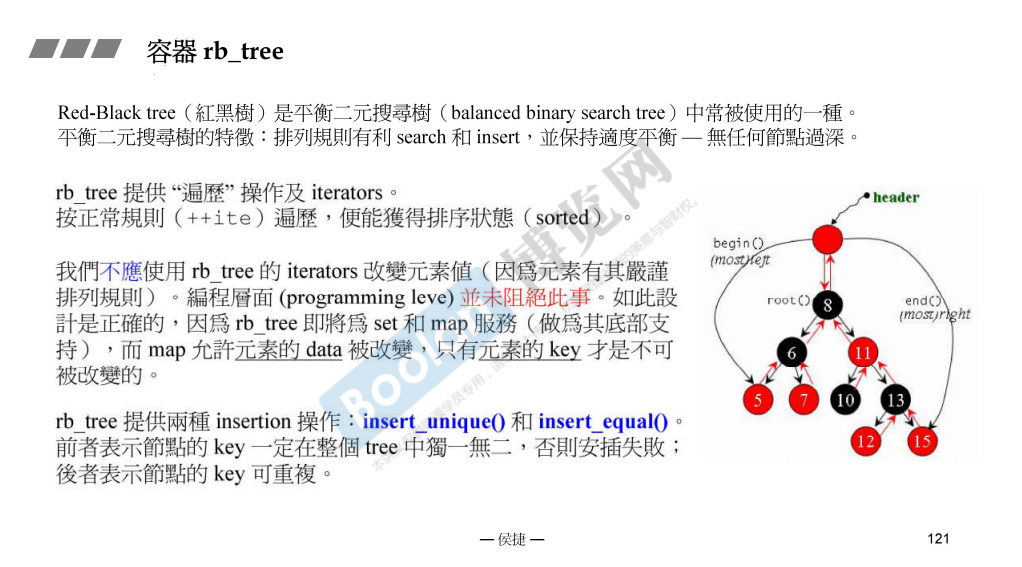
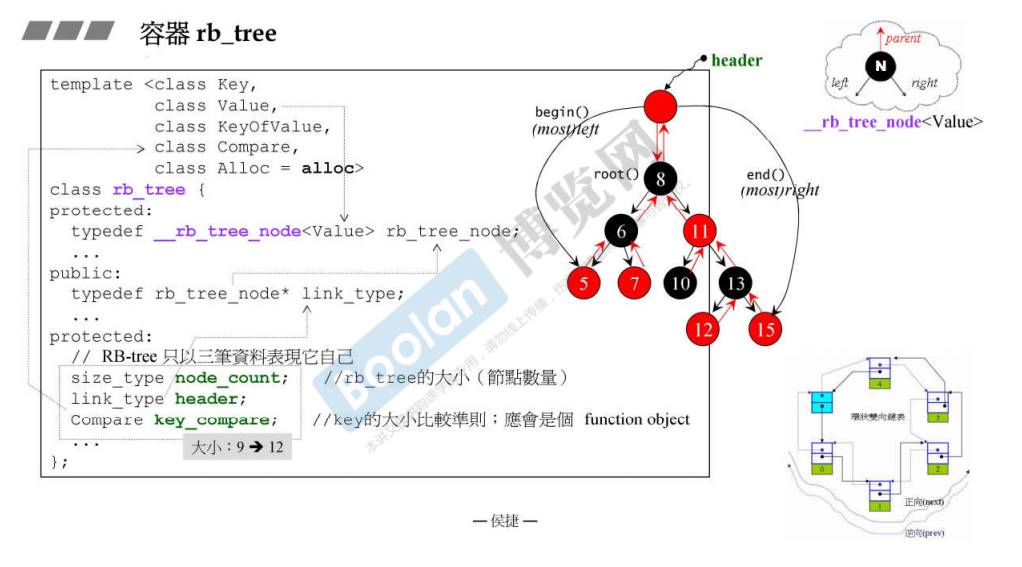
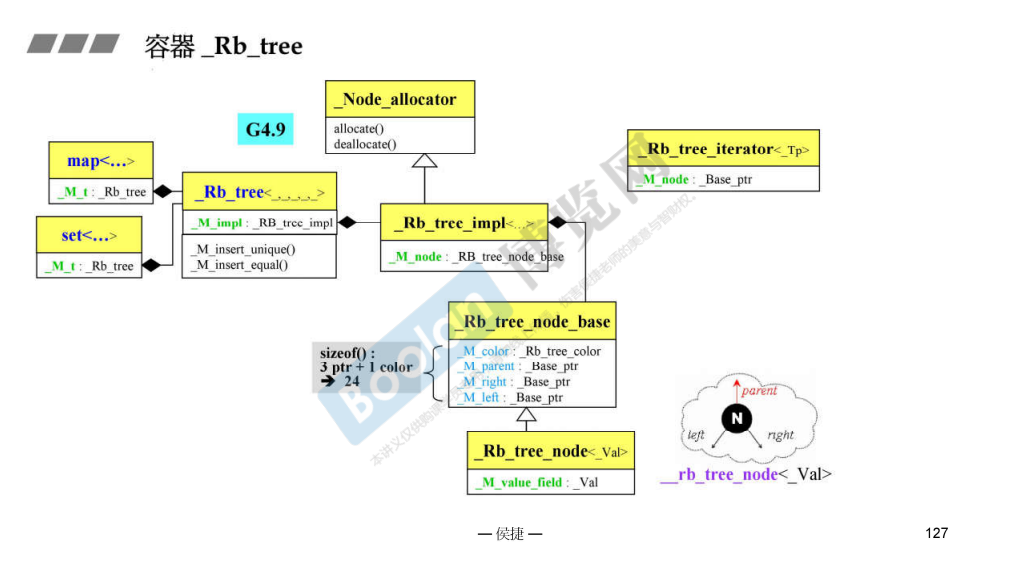
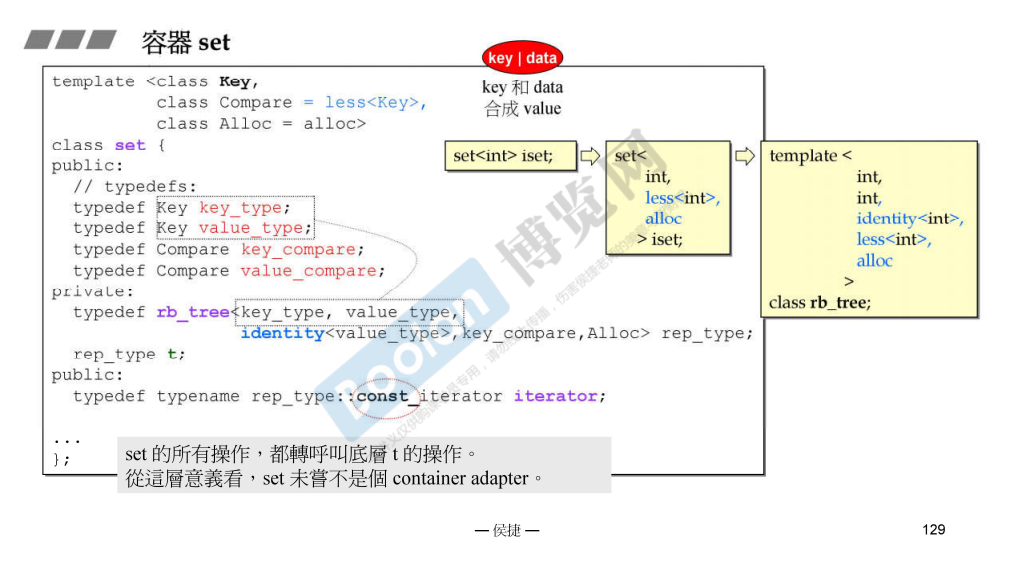
set
有两个不同的操作,所以 multi_set 能够实现。
在目前的 MSVC 中,_Tree 增加了一个表示是否支持重复的选项,所以 API 有部分不同。
1 2 3 4 auto itree = _Tree<_Tset_traits<int , less<int >, allocator<int >, false >>(less <int >());auto mtree = _Tree<_Tset_traits<int , less<int >, allocator<int >, true >>(less <int >());
基本结构都是比较类似的:
1 2 3 4 _Allocator \/ container ()- | data_structure | | -> _M_impl: _ds_impl | ()- | _ds_impl | ()- | _Node_base | ()- | _Node |
容器 set 大部分都是直接复用了 RBTree 的方法,MSVC 中的实现也是一样的。
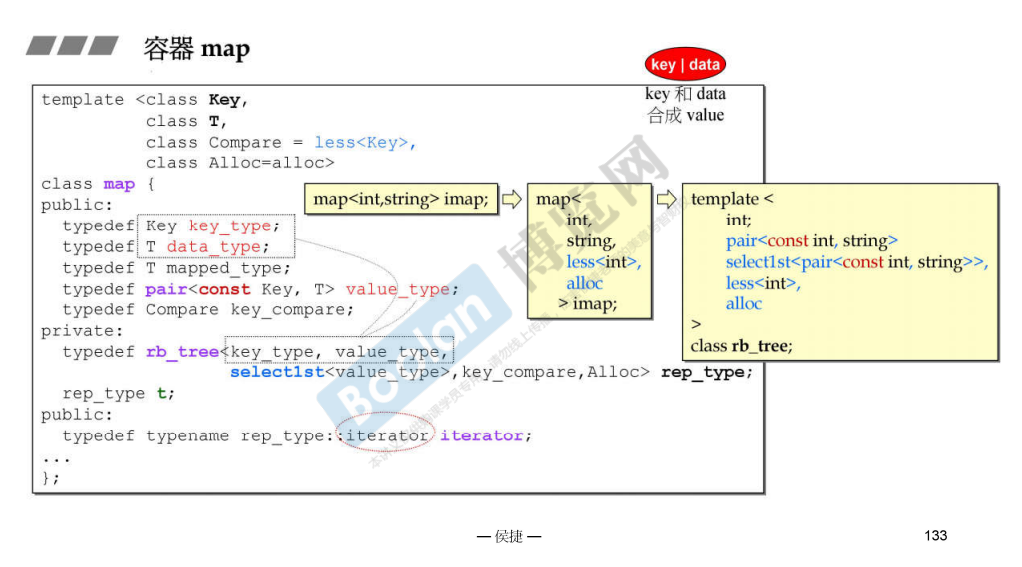
map
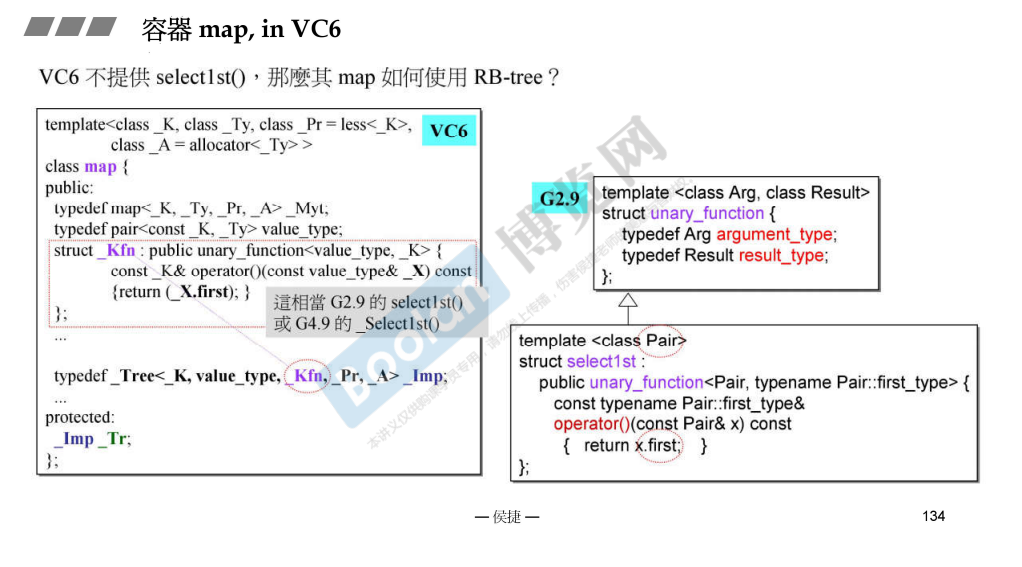
map 也跟 set 类似,但是 map 中的红黑树的元素是 pair<const int, string> ,const 防止 key 被修改。中间还使用了适配器 select1st ,应该是选择第一个类型(毕竟这里是类声明部分)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct less_than_7 : std::unary_function<int , bool >{ bool operator () (int i) const return i < 7 ; } }; int main () std::vector<int > v; for (int i = 0 ; i < 10 ; ++i) v.push_back (i); std::cout << std::count_if (v.begin (), v.end (), std::not1 (less_than_7 ())); }
顺带学习了一下 decltype(lambda) 。由于 lambda 创建时就必须指定一个变量,所以想要获取一个 lambda 的类型是不行的。如下代码会导致错误:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 std::function<bool (const int , const int )> cmp = [] (const int a, const int b) { return a < b; }; struct mycmp { bool operator () (int a, int b) const return a < b; } }; set<int , mycmp> s; s.insert (1 ); s.insert (4 ); s.insert (3 ); s.insert (2 );
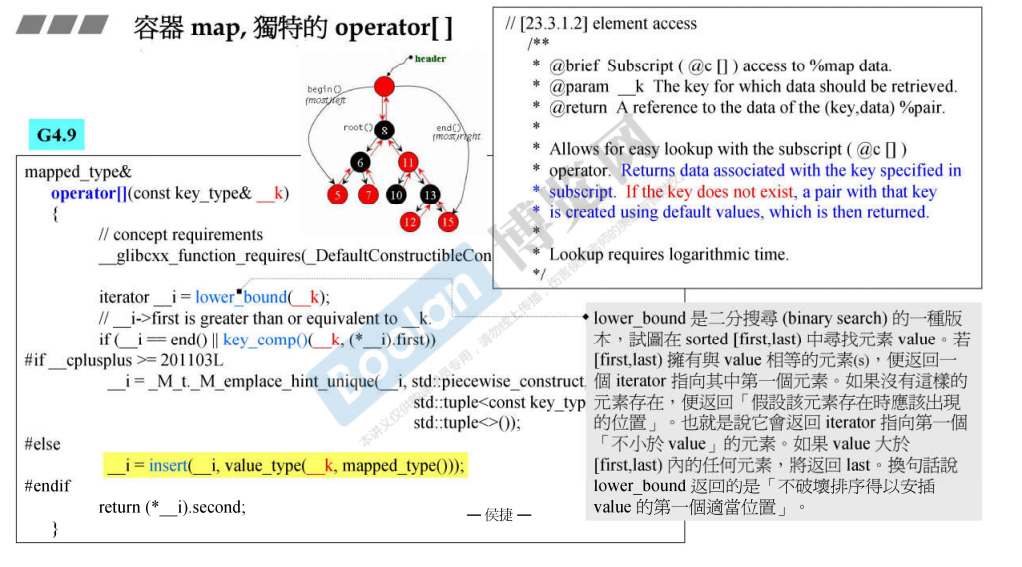
map 中的 operator[] 先查找到相应位置,如果不存在对应的 key,就执行插入操作,即 insert ,最后返回指向第二个元素的引用。因为 map 中存储的 pair<_Key, _Value> 对象,所以 foreach 循环得到的也是这个对象。
TODO:没看得太明白,需要再看一遍,以及 msvc 的实现 。
lower_bound ,下确界,返回不小于 value 的元素的位置,也即插入 value 的位置。upper_bound ,上确界,返回第一个大于(不包括等于)value 的元素的位置。或者我们也可以理解,lower_bound(下确界),upper_bound(上确界),都是返回一个不破坏排序的位置 。这需要迭代器返回的数据必须是有序的 ,因此,排序后的 vector、deque 等,以及内部有序的 set、map 等都可以使用。
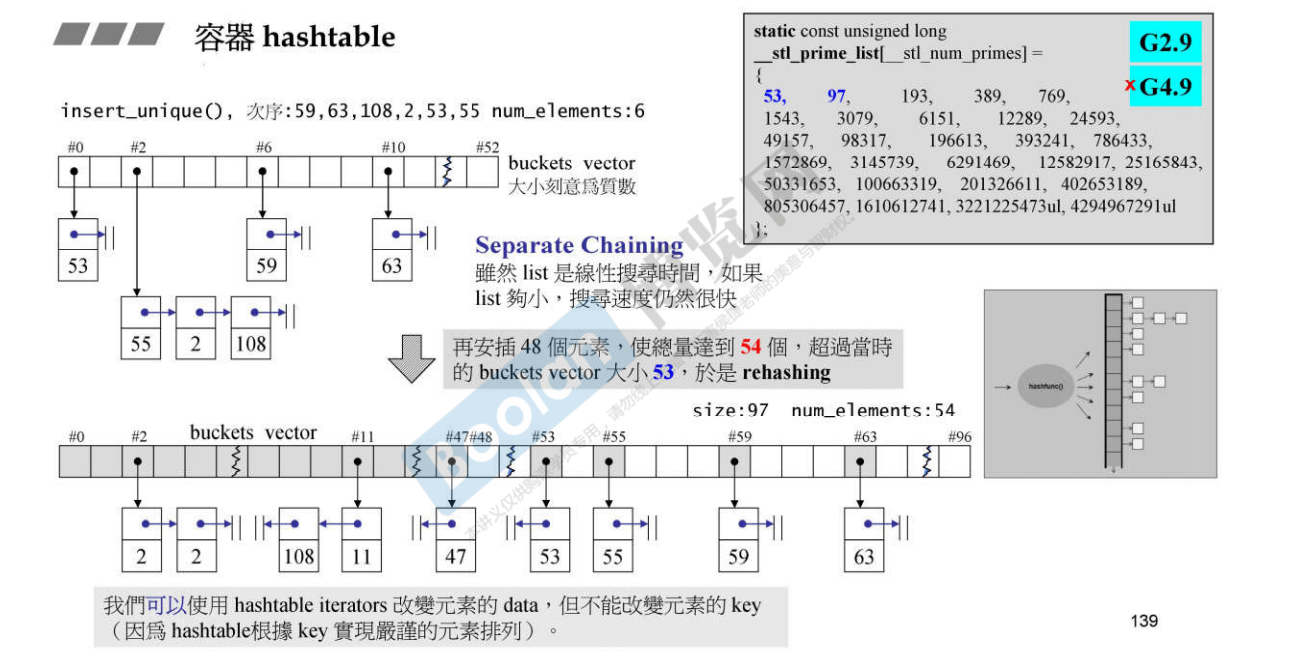
图中还展示了哈希表的 rehash,当容量超过给出的素数哈希长度时,便会发生 rehash。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 _NODISCARD size_type _Desired_grow_bucket_count(const size_type _For_size) const noexcept { const size_type _Old_buckets = bucket_count (); const size_type _Req_buckets = (_STD max)(_Min_buckets, _Min_load_factor_buckets(_For_size)); if (_Old_buckets >= _Req_buckets) { return _Old_buckets; } if (_Old_buckets < 512 && _Old_buckets * 8 >= _Req_buckets) { return _Old_buckets * 8 ; } return _Req_buckets; }
C++ 中的 unordered_map 使用哈希函数将键值对映射到一个哈希表中,这样就可以以常数时间复杂度实现查找操作。unordered_map 默认使用 std::hash 类型的哈希函数,可以通过模板参数自定义哈希函数。unordered_map 是无序的,查找效率比 map 高,但是无序性也意味着每次插入都可能会造成哈希表中所有元素的重新分布,因此插入操作的时间复杂度可能变成 O(n) 。
std::hash 类型的哈希函数是 C++ 标准库提供的一种常见的哈希函数实现,它可以用于任何类型的 key,只需要 key 类型有符合 std::hash 的接口要求:提供一个接受一个 key 类型,返回一个 std::size_t 整数的函数,即 std::size_t operator() (Key const &key) const 。具体的实现可以是任意的,只要能够保证在一定范围内,不同的 key 会得到不同的哈希值即可。如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct Person { string name = "Peter" ; int age = 10 ; }; struct PersonHash { size_t operator () (Person const &p) const return p.name.length () + p.age; } }; struct PersonEqual { bool operator () (Person const &p1, Person const &p2) const return p1.name == p2.name && p1.age == p2.age; } }; int main (int argc, char ** argv) unordered_map<Person, int , PersonHash, PersonEqual> personToDepart; personToDepart[Person{"Tom" , 20 }] = 0 ; for (auto personDepartPair : personToDepart) { cout << "Name: " << personDepartPair.first.name << ", Age: " << personDepartPair.first.age << ", Department: " << personDepartPair.second << endl; } return 0 ; }
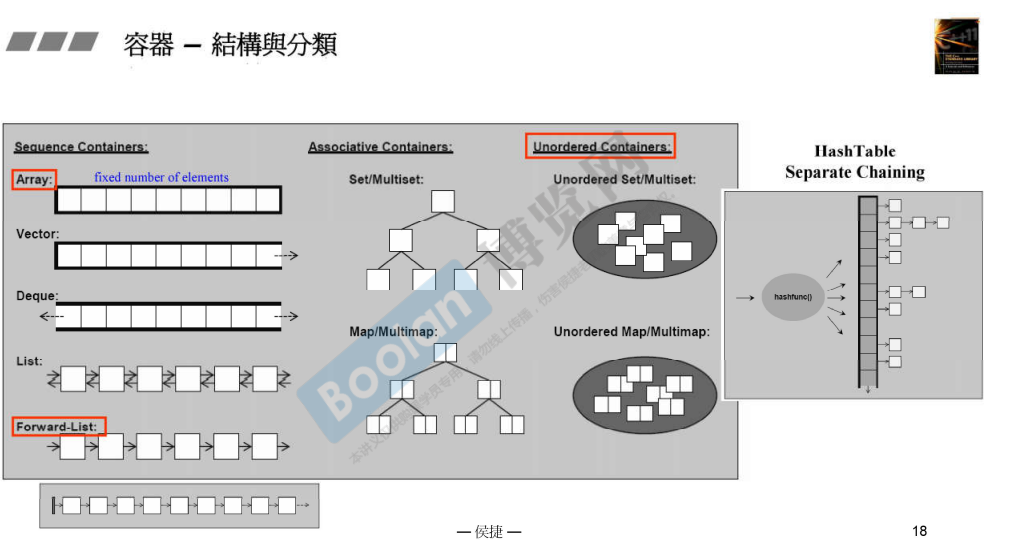
由于可能有多个 key 映射到同一个哈希值上,叫做哈希冲突。为了解决哈希冲突,一般有两种方法:开放地址法和拉链法,图中展示的就是拉链法。
开放地址法是当发生哈希冲突时,使用另一个地址来存储元素,而这个地址是在哈希函数的基础上增加一个大于 0 的数的偏移量 ,这个偏移量称为解决冲突的方法。拉链法是在每个地址处存储一个指针,指向一个链表 ,存储着所有冲突的元素,当有新元素插入时,将新元素插入此链表中。
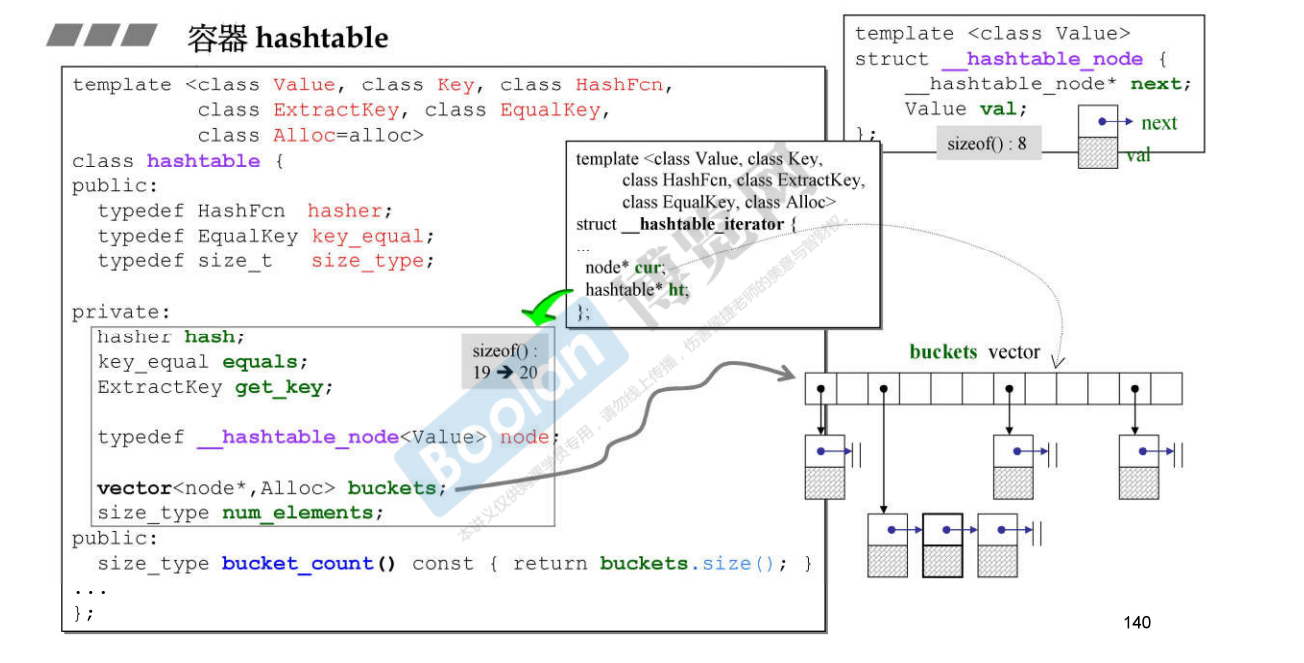
图中展示了 hashtable 的成员变量,以及哈希表 buckets 。
对于 int 类型的数据,散列值就等于本身;对于 string 类型的数据,散列值等于上面给出的算法。对于 Person 类的实现如下:
1 2 3 4 5 6 7 8 9 10 struct PersonHash { size_t operator () (Person const &p) const size_t hashCode = 0 ; for (auto & c : p.name) { hashCode = 5 * hashCode + c; } return hashCode + p.age; } };
经过测试,插入顺序和迭代器访问的顺序是不一样的。由于哈希冲突的存在,先插入的数据可以被先访问(在链表内)。因此,它被叫做 unordered_map 。
Iterator
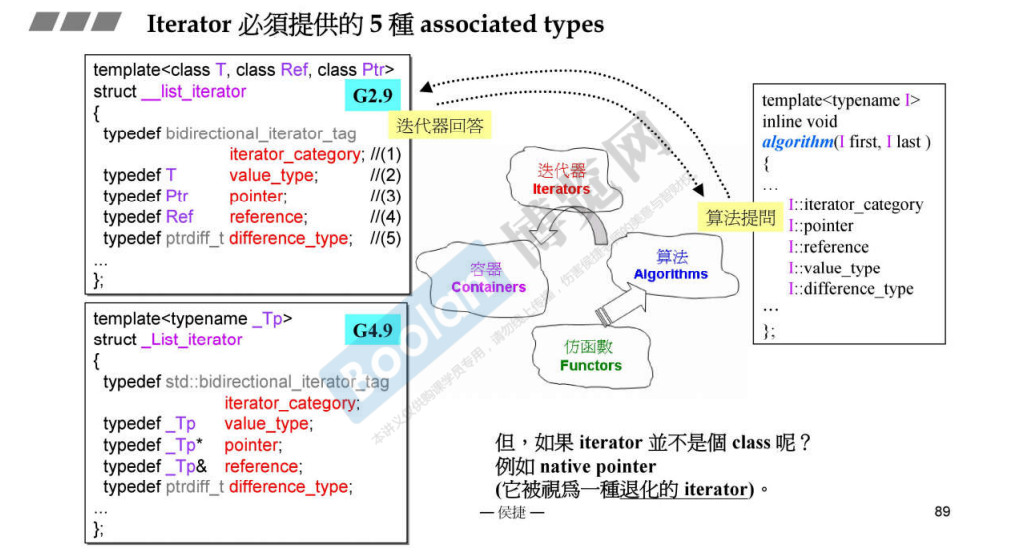
迭代器 iterator 有五种类型,如下:
1 2 3 4 5 6 7 8 9 struct input_iterator_tag {};struct output_iterator_tag {};struct forward_iterator_tag : input_iterator_tag {};struct bidirectional_iterator_tag : forward_iterator_tag {};struct random_access_iterator_tag : bidirectional_iterator_tag {};
最简单的迭代器就是输入输出迭代器,输入输出最简单的应用就是输入输出流。输入迭代器只能前进和读取,不能写入;输出迭代器只能后退和写入,不能读取。
各个迭代器的例子:
Input Iterator:输入流,只能读取,支持 ++、==、!=
Forward Iterator:单链表,可写入可读取,只能 ++
Bidirectional Iterator:双向链表,可读取可写入,可++、–
RandomAccess Iterator:数组,可读取可写入,可 ++、- -、[]、+n
Output Iterator:输出流,只能写入,++
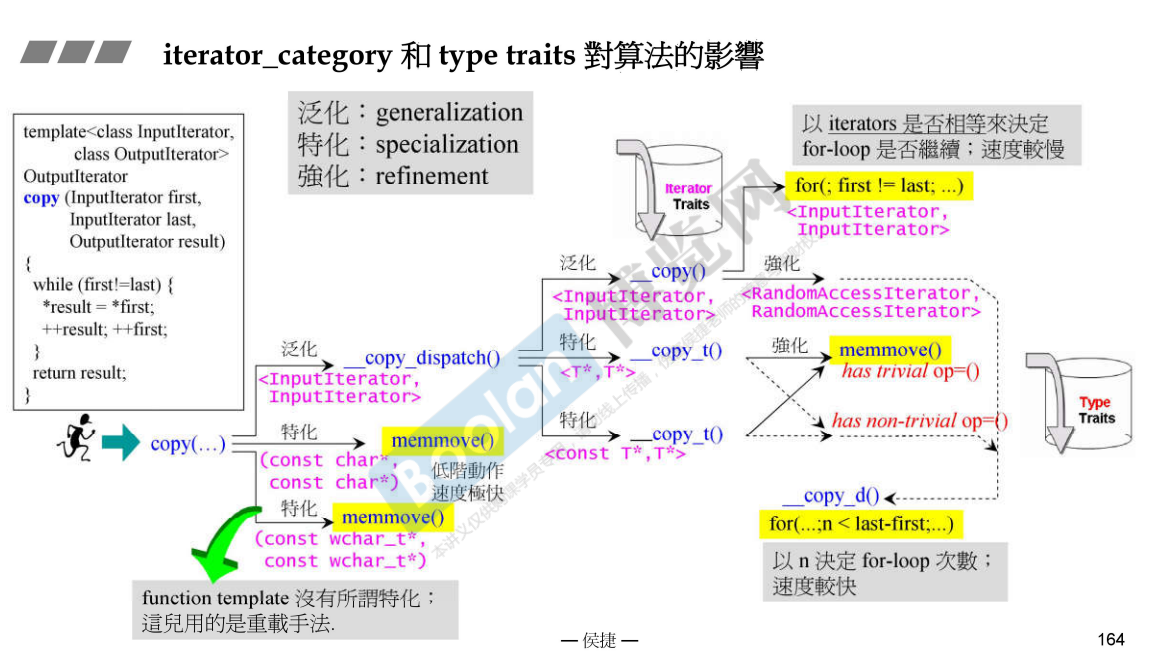
类型的不同,导致了实现的不同。随机访问迭代器可以直接相减。
迭代器复制,分为以下情况:
char* :一个 char 是一字节,所以最符合内存的结构要求。(这里的示意换成 short 也可以)T* :指针全都在内存中,可能可以直接复制
has trivial op=() :存在简单的拷贝赋值函数,应该是表示这个类型是一个 POD(plain old data)结构has non-trival op=() :不是 POD,可能有虚函数
RandomAccessIterator :可以直接相减得到距离,不需要判断指针相等,有利于编译器优化InputIterator :只能判断指针是否相等,必须等到运行时
output iterator 不能直接读取,所以要先解引用,然后再写入。forward iterator 没有这个限制。
这部分已经是暗示了,基本上指名是什么迭代器就必须用什么迭代器。
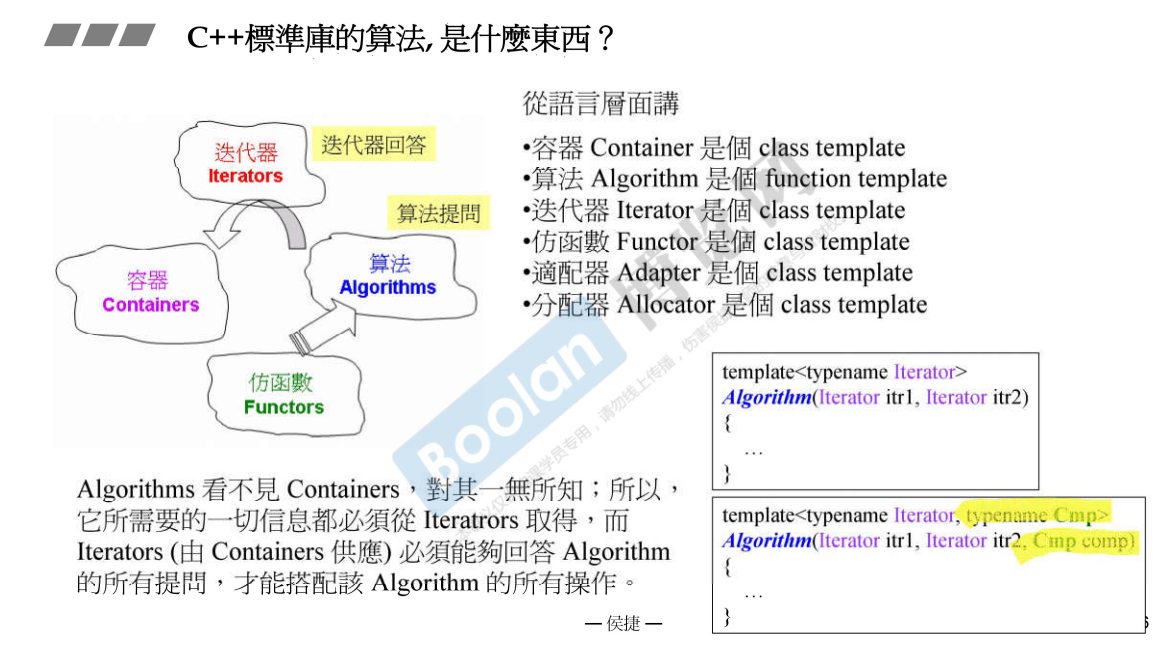
Algorithms 后面是一部分函数的介绍:
不带有 count 的容器都是序列容器,而不是关联式容器。
注意:unordered_set 等四个哈希表容器的顺序是基于哈希顺序和插入顺序
Functors
看到这部分的 binary_function,以及下面的 operator() ,其实跟 lambda 差不多:
1 2 3 4 5 6 7 8 9 struct MyLess : public binary_function<int , int , bool > { bool operator () (const int & a, const int & b) const return a < b; } }; std::function<bool (int , int )> myLess = [] (const int & a, const int & b) { return a < b; };
缺点可能是 std::function 目前只修饰 lambda,而 binary_function 可以作为基类。
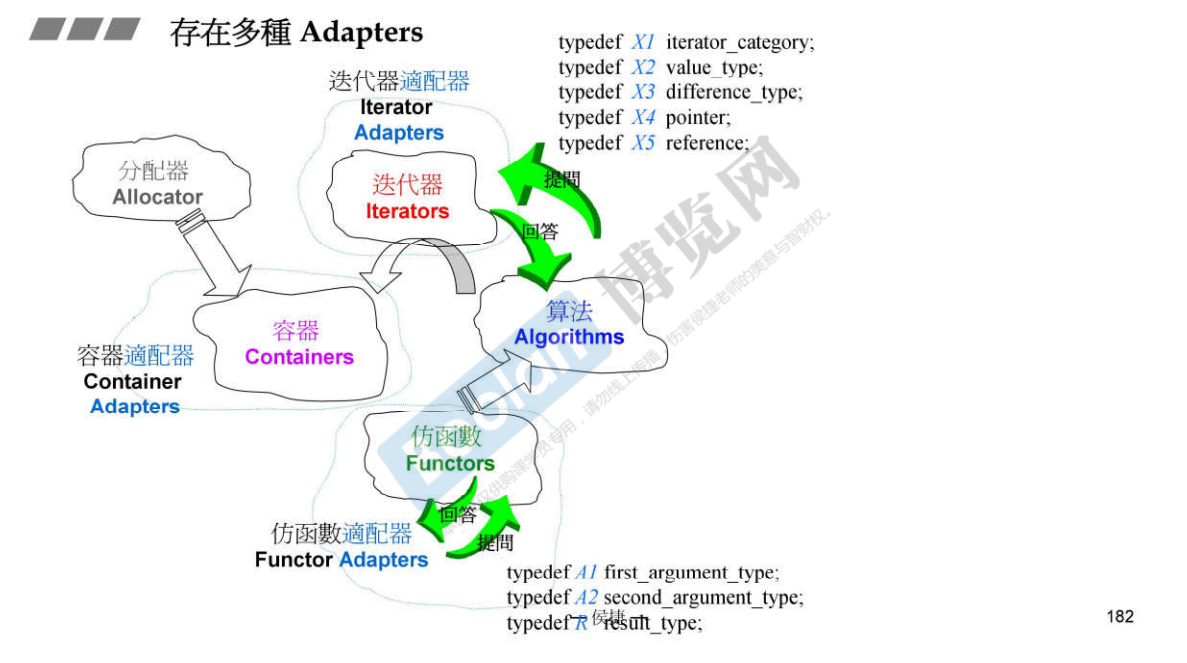
容器适配器的含义就是通过该适配器的包装,使得容器能够拥有某些额外的功能,或者说抽象出一些额外的特性。vector 可以被包装成一个 stack,deque 去掉双向的条件,也能变成一个单向队列 queue。
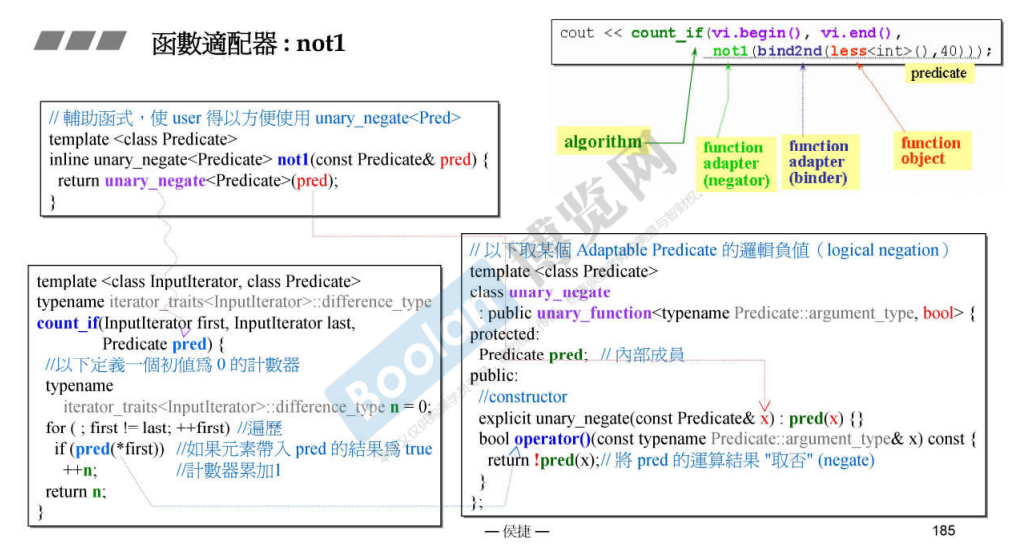
函数适配器修饰函数(这里的函数是广义的,能够调用 operator() 的仿函数、函数指针),使得函数的一些性质发生变化。上面两张图描述了 not1(bind2nd(less<int>(), 40)); 中的两个函数适配器,及其实现。
函数适配器能够在运行时改变函数的性质,而不需要修改函数本身的内容。
新型的适配器 bind,可以实现以下操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vector<int > v; for (int i = 0 ; i < 50 ; i++) v.push_back (i); cout << count_if (v.begin (), v.end (), bind ([] (int & a, int &b) { return a < b; }, placeholders::_1, 40 )) << endl; cout << count_if (v.begin (), v.end (), bind (less <int >(), placeholders::_1, 40 )) << endl; cout << count_if (v.begin (), v.end (), bind ([] (int & a, int & b, int & c) { return a < b && a >= c; }, placeholders::_1, 40 , 14 )) << endl;
感觉如果通过手写 lambda 的方式,可以达到更高效的使用。
下面是 MSVC 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 template <class _Ret , class _Fx , class ... _Types>class _Binder : public _Binder_result_type<_Ret, _Fx>::type { private : using _Seq = index_sequence_for<_Types...>; using _First = decay_t <_Fx>; using _Second = tuple<decay_t <_Types>...>; _Compressed_pair<_First, _Second> _Mypair; public : constexpr explicit _Binder(_Fx&& _Func, _Types&&... _Args) : _Mypair(_One_then_variadic_args_t{}, _STD forward<_Fx>(_Func), _STD forward<_Types>(_Args)...) {} #define _CALL_BINDER \ _Call_binder(_Invoker_ret<_Ret> {}, _Seq{}, _Mypair._Get_first(), _Mypair._Myval2, \ _STD forward_as_tuple(_STD forward<_Unbound> (_Unbargs)...)) template <class ... _Unbound> _CONSTEXPR20 auto operator () (_Unbound&&... _Unbargs) noexcept (noexcept (_CALL_BINDER)) -> decltype (_CALL_BINDER) { return _CALL_BINDER; } template <class ... _Unbound> _CONSTEXPR20 auto operator () (_Unbound&&... _Unbargs) const noexcept (noexcept (_CALL_BINDER)) -> decltype (_CALL_BINDER) { return _CALL_BINDER; } #undef _CALL_BINDER };
count_if 中的第三个参数肯定会是 BinaryOperation,所以 bind 的返回值也肯定需要是一个重载了函数运算符 operator() 的类型。通过 C++11 的多变量泛型,支持了同时输入多个参数。
TODO :forward 的实现是如何的?
forward 的实现是通过右值引用和类型推断来实现的。它是一个模板函数,它可以接受一个参数,并且返回一个引用,该引用类型与传入的参数类型相同。如果传入的参数是左值,则返回一个左值引用,如果传入的参数是右值,则返回一个右值引用。
例如:
1 2 3 4 5 template <typename T>T&& forward (typename std::remove_reference<T>::type& t) noexcept { return static_cast <T&&>(t); }
使用 std::remove_reference 可以去掉引用的类型,然后使用 static_cast 来保持原有的引用类型,这样就可以实现 forward 的功能了。
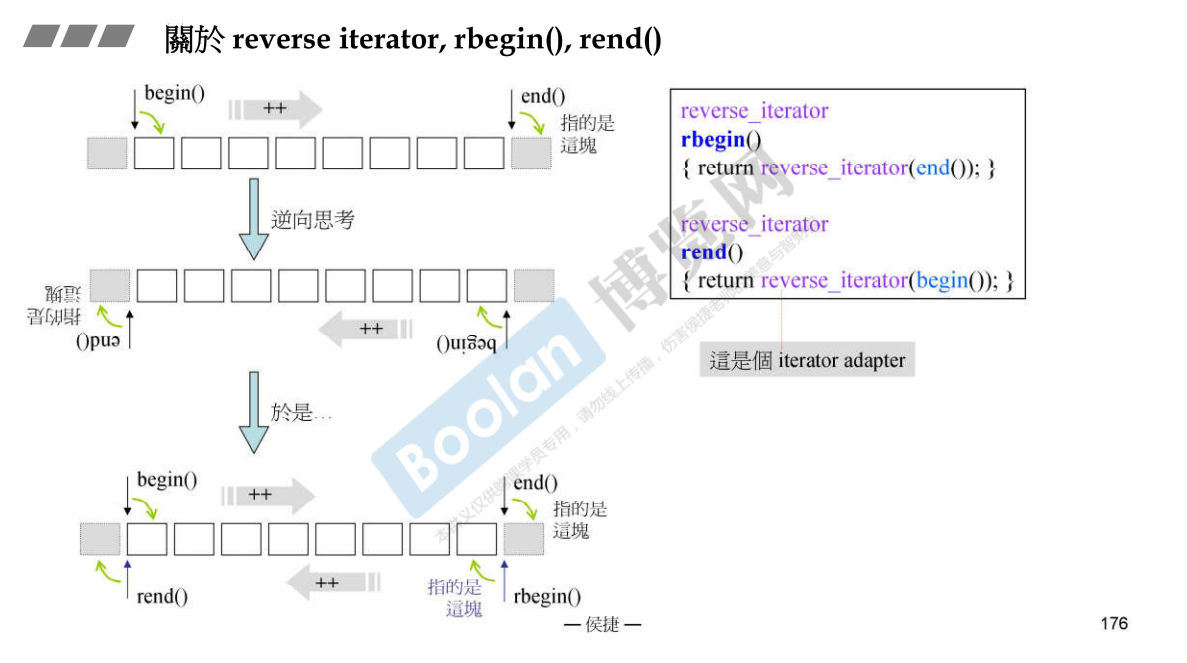
迭代器适配器,给迭代器加上限制。反转适配器,可以由 begin() 得到 rbegin() 。
插入适配器,插入适配器定义自己的 category 一定是一个 output_iterator_tag,所以只能前进和写入,其实是符合使用要求的。inserter 通过迭代器 insert 返回的迭代器,不断更新自己类内部的迭代器,从而实现一直贴着最新的插入位置。
MSVC 的实现一模一样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 template <class _Container >_NODISCARD _CONSTEXPR20 insert_iterator<_Container> inserter ( _Container& _Cont, typename _Container::iterator _Where) return insert_iterator <_Container>(_Cont, _Where); } template <class _Container >class insert_iterator { public : using iterator_category = output_iterator_tag; using value_type = void ; using pointer = void ; using reference = void ; _CONSTEXPR20 insert_iterator (_Container& _Cont, _Wrapped_iter _Where) : container(_STD addressof(_Cont)), iter(_STD move(_Where)) { } _CONSTEXPR20 insert_iterator& operator =(const typename _Container::value_type& _Val) { iter = container->insert (iter, _Val); ++iter; return *this ; } _CONSTEXPR20 insert_iterator& operator =(typename _Container::value_type&& _Val) { iter = container->insert (iter, _STD move (_Val)); ++iter; return *this ; } }
输出流适配器,可以按照迭代器的性质,把数据输出到输出流中。这里的输出流可以包括,string 输出流、标准输出流、文件输出流。
1 2 3 4 5 6 7 8 stringstream ss; ostream_iterator<int > osi (ss, " " ) ;copy (v.begin (), v.end (), osi);cout << ss.str () << endl; ofstream ofs ("test.txt" , ios_base::app) ; ostream_iterator<int > fosi (ofs, " " ) ;copy (v.rbegin (), v.rend (), fosi);
注意:这些输出流本身没有带对应的迭代器,需要自己定义,然后才能调用。
MSVC 的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <class _Ty , class _Elem = char , class _Traits = char_traits<_Elem>>class ostream_iterator {public : using iterator_category = output_iterator_tag; using value_type = void ; #ifdef __cpp_lib_concepts using difference_type = ptrdiff_t ; #else using difference_type = void ; #endif using pointer = void ; using reference = void ; using char_type = _Elem; using traits_type = _Traits; using ostream_type = basic_ostream<_Elem, _Traits>; ostream_iterator (ostream_type& _Ostr, const _Elem* const _Delim = nullptr ) noexcept : _Mydelim(_Delim), _Myostr(_STD addressof (_Ostr)) {} ostream_iterator& operator =(const _Ty& _Val) { *_Myostr << _Val; if (_Mydelim) { *_Myostr << _Mydelim; } return *this ; } }
实际上就是调用输出流的重载 operator<< 函数进行输出,如果有分隔符,就调用分隔符。
输入流迭代器。原理跟输出流迭代器类似,测试如下:
1 2 istream_iterator<int > iis (cin) , eof ;copy (iis, eof, fosi);
读取输入流的数据,然后输出的文件中。
同样,我们也可以实现直接插入数据到 vector 的迭代器中:
1 copy (iis, eof, inserter (v, v.end ()));
一定需要添加 inserter 适配器,因为不加的话,v.end() 不会随着数据的增加而不断移动。
实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 template <class T >inline void hash_combine (size_t & seed, const T& t) seed ^= std::hash <T>()._Do_hash(t) + 0x9e3779b9 + (seed << 6 ) + (seed >> 2 ); } template <class T >inline void hash_val (size_t & seed, const T& t) hash_combine (seed, t); } template <typename T, typename ... Types>inline void hash_val (size_t & seed, const T& t, const Types&... args) hash_combine (seed, t); hash_val (seed, args...); } template <class ... Types>inline size_t hash_val (const Types&... args) size_t seed = 0 ; hash_val (seed, args...); return seed; } struct Person { Person (string name, int age) : name (name), age (age) {} string name; int age; }; struct NaivePersonHash { size_t operator () (const Person& p) const std::hash<string> h1; std::hash<int > h2; return h1._Do_hash(p.name) + h2._Do_hash(p.age); } }; struct PersonHash { size_t operator () (const Person& p) const return hash_val (p.name, p.age); } };
万能 hash 函数中的 magic number 就是黄金分割中的数,黄金比例 $\frac{1+\sqrt{5}}{2}$,转换为 16 进制,为 1.9E3779B97F... 。算法通过泛型实现了同时输入多个参数,只要 std::hash<>() 支持这个哈希值,那就可以实现。
还写了一个分割器:
1 2 3 4 5 6 7 8 9 10 11 template <char Sign, int num>struct Divider { };template <char Sign='-' , int num=50 >std::ostream& operator <<(std::ostream& os, Divider<Sign, num>) { for (int i = 0 ; i < num; i++) os << Sign; return os; } cout << Divider <'-' , 50 >() << endl;
偏特化指的是 hash<T> 不是一个完整的类型,还需要 typename 进行指定。
大部分讲解了 tuple 的用例,下面利用泛型打印 tuple 元素的实现很重要(so 上抄的 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 template <typename Type, unsigned N, unsigned Last>struct tuple_printer { static void print (std::ostream& out, const Type& value) out << std::get <N>(value) << ", " ; tuple_printer<Type, N + 1 , Last>::print (out, value); } }; template <typename Type, unsigned N>struct tuple_printer <Type, N, N> { static void print (std::ostream& out, const Type& value) out << std::get <N>(value); } }; template <typename ...Types>std::ostream& operator <<(std::ostream& os, std::tuple<Types...> t) { os << "(" ; tuple_printer<std::tuple<Types...>, 0 , sizeof ...(Types) - 1 >::print (os, t); return os << ")" ; }
通过泛型上给定的开始和结束的两个参数,当两个参数相等时就调用第二个 print。
MSVC 上的实现不一样,课件上的实现是通过继承实现的。
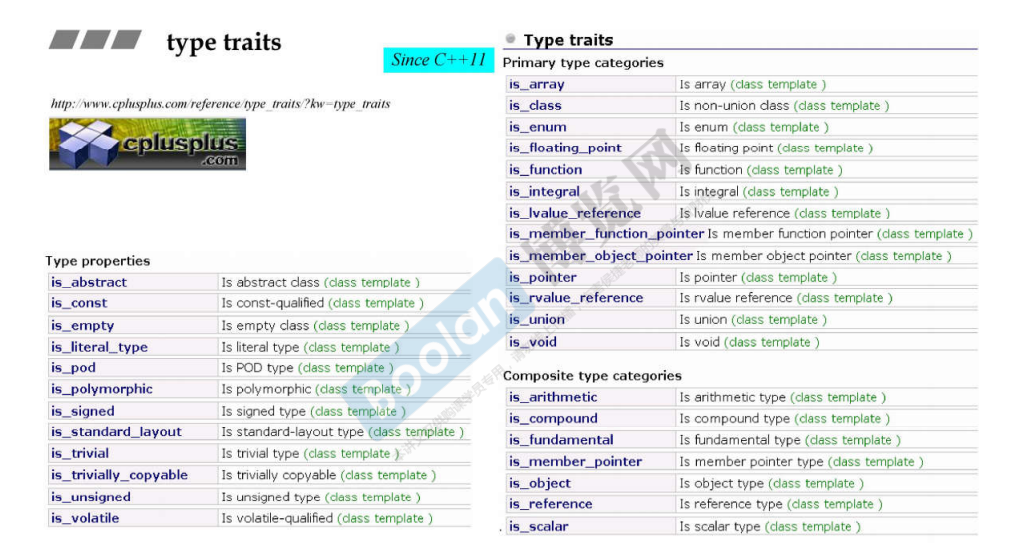
类型分析,traits 特性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 template <typename T>void type_traits_output (const T& x) std::cout << "intype traits for type : " << typeid (T).name () << std::endl; std::cout << "is_void\t" << std::is_void<T>::value << std::endl; std::cout << "is_integral\t" << std::is_integral<T>::value << std::endl; std::cout << "is_floating _point\t" << std::is_floating_point<T>::value << std::endl; std::cout << "is_arithmetic\t" << std::is_arithmetic<T>::value << std::endl; std::cout << "is_signed\t" << std::is_signed<T>::value << std::endl; std::cout << "is_unsigned\t" << std::is_unsigned<T>::value << std::endl; std::cout << "is_const\t" << std::is_const<T>::value << std::endl; std::cout << "is_volatile\t" << std::is_volatile<T>::value << std::endl; std::cout << "is_class\t" << std::is_class<T>::value << std::endl; std::cout << "is_function\t" << std::is_function<T>::value << std::endl; std::cout << "is_reference\t" << std::is_reference<T>::value << std::endl; std::cout << "is_lvalue_ reference\t" << std::is_lvalue_reference<T>::value << std::endl; std::cout << "is_rvalue_reference\t" << std::is_rvalue_reference<T>::value << std::endl; std::cout <<"is_pointer\t" << std::is_pointer<T>::value << std::endl; std::cout << "is_member _pointer\t" << std::is_member_pointer<T>::value << std::endl; std::cout << "is_member_object_pointer\t" << std::is_member_object_pointer<T>::value << std::endl; std::cout << "is_member_function_pointer\t" << std::is_member_function_pointer<T>::value << std::endl; std::cout << "is_fundamental\t" << std::is_fundamental<T>::value << std::endl; std::cout <<"is_scalar\t" << std::is_scalar<T>::value << std::endl; std::cout << "is_object\t" << std::is_object<T>::value << std::endl; std::cout << "is_compound\t" << std::is_compound<T>::value << std::endl; }
注意,以下二者调用的结果是相同的:
1 2 cout << std::is_floating_point<T>::value << endl; cout << std::is_floating_point_v<T> << endl;
type traits 的实现,基于 MSVC 的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 template <class _Ty >_INLINE_VAR constexpr bool is_void_v = is_same_v<remove_cv_t <_Ty>, void >; template <class _Ty >struct remove_cv <const volatile _Ty> { using type = _Ty; template <template <class > class _Fn > using _Apply = const volatile _Fn<_Ty>; }; template <class _Ty >using remove_cv_t = typename remove_cv<_Ty>::type;_INLINE_VAR constexpr bool is_same_v = __is_same(_Ty1, _Ty2);
实现细节:
remove_cv :去除 const volatile 限定符,通过泛型,以及在泛型名前加上 <const volatile _Ty> 实现。is_same_v :编译器实现细节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 template <bool _First_value, class _First , class ... _Rest>struct _Disjunction { using type = _First; }; template <class _False , class _Next , class ... _Rest>struct _Disjunction <false , _False, _Next, _Rest...> { using type = typename _Disjunction<_Next::value, _Next, _Rest...>::type; }; template <class ... _Traits>struct disjunction : false_type {}; template <class _First , class ... _Rest>struct disjunction <_First, _Rest...> : _Disjunction<_First::value, _First, _Rest...>::type { }; template <class ... _Traits>_INLINE_VAR constexpr bool disjunction_v = disjunction<_Traits...>::value; template <class _Ty , class ... _Types>_INLINE_VAR constexpr bool _Is_any_of_v = disjunction_v<is_same<_Ty, _Types>...>; template <class _Ty >_INLINE_VAR constexpr bool is_integral_v = _Is_any_of_v<remove_cv_t <_Ty>, bool , char , signed char , unsigned char , wchar_t , #ifdef __cpp_char8_t char8_t , #endif char16_t , char32_t , short , unsigned short , int , unsigned int , long , unsigned long , long long , unsigned long long >;
泛型传递,应该是泛型编程中的 for
disjunction_v :SQL 中的连接,即如果有一个为真,那么就成功disjunction_v<is_ame<_Ty, _Types>...> :… 表示泛型的推导,表示不断传递下去,作为 for上面的三个 _Disjunction 应该起到了 if、else 的基础,同时还有部分 for 的功能
MSVC 与上图一样,全都使用的是编译器的实现。
MSVC 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template <class _Ty , class = void >struct _Add_reference { using _Lvalue = _Ty; using _Rvalue = _Ty; }; template <class _Ty >struct _Add_reference <_Ty, void_t <_Ty&>> { using _Lvalue = _Ty&; using _Rvalue = _Ty&&; }; template <class _Ty >using add_lvalue_reference_t = typename _Add_reference<_Ty>::_Lvalue;template <class _Ty >_INLINE_VAR constexpr bool is_move_assignable_v = __is_assignable(add_lvalue_reference_t <_Ty>, _Ty);
通过添加两个引用,来判断跟原来的类型是否相同。
G2.9 和 G4.9 的实现不同,一个是普通的继承,一个利用了大量的泛型技术。
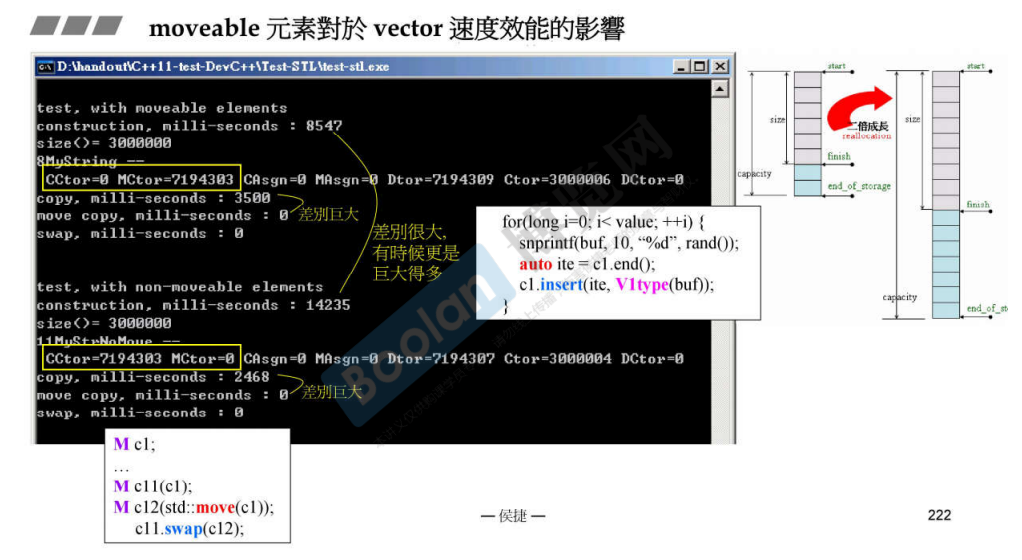
C++ 11 引入的移动语义对效率的提升巨大。特别是很多场景下,并不需要保持多个变量的拷贝。也因此,类似 Java、python 都是默认引用,而不是值传递。
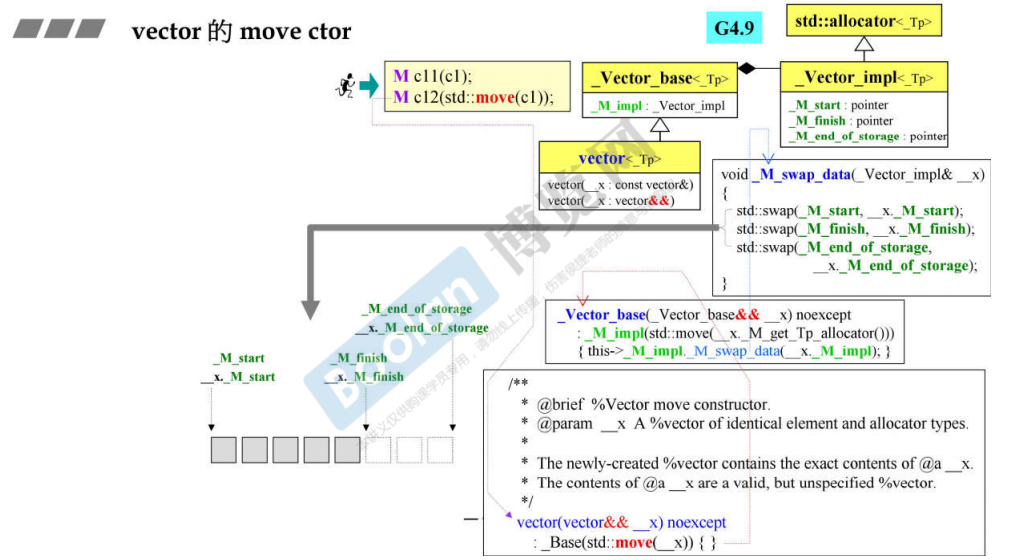
vector 的拷贝构造和移动构造的区别:
拷贝构造:分配头节点地址,拷贝数据,分配尾节点地址
移动构造:使用了三个 swap 实现,只需要交换指针的地址即可,非常简单