ORT 模型部署
Deploy ORT model
onnxruntime-inference-examples/mobilenet.ipynb at main · microsoft/onnxruntime-inference-examples
真正部署模型,不应该把后处理包括在模型推理中,这会影响模型在GPU上的部署,性能也不一定会好。这里的后处理,不仅仅是model(input) 之后的,也可以是作者放在模型推理过程中,但是实际上可以归为后处理的部分。
判断函数是否在ONNX trace的过程中:torch.onnx.is_in_onnx_export() 。
Torch to ONNX
- torch不支持
F.grid_sample算子。从ONNX支持的算子列表来看,opset=16时,可以直接使用grid_sampler而不需要手动设置符号函数。
1 | # https://github.com/pytorch/pytorch/issues/27212#issuecomment-1059773074 |
_DCNv2完全不受支持。它是用CUDA编译的,无论是自带的DCNv2还是mmcv的DCNv2。
1 |
|
在这里可以注册一个符号函数(symbolic_function)来自己手动通过cpp实现DCNv2,但是我其实并不确定它能不能运行到mobile端。最上面导出NCNN的方法其实说过,可以跳过它,就是不用它,换到一个Conv层就行。在实现层面上,参考下面的模型变量key:
1 | 5:'dla.ida_up.proj_1.conv.weight' |
它自带了一个conv,同时还有一个conv_offset_mask来学习stride的微小偏移量,这使得我们可以不使用后面的conv_offset_mask,只使用conv本身的权重来推理。不过这样会丢掉一些性能。下面这个用的是TensorRT推理,所以可以支持CUDA。DCNv2的实现中,其中一个就是参考了这个repo的。它这里面实现了自定义的算子,并且用符号函数把算子和onnx计算图联系到了一起。
TensorRT-CenterNet/ctdet2onnx.md at master · CaoWGG/TensorRT-CenterNet
Floating point exception (core dumped)。这个报错出现地非常地无厘头,因为它没有任何报错栈,只是单纯地显示它出错了。如果用torch1.9,会有更多的报错信息,虽然基本上也看不了。截图如下:
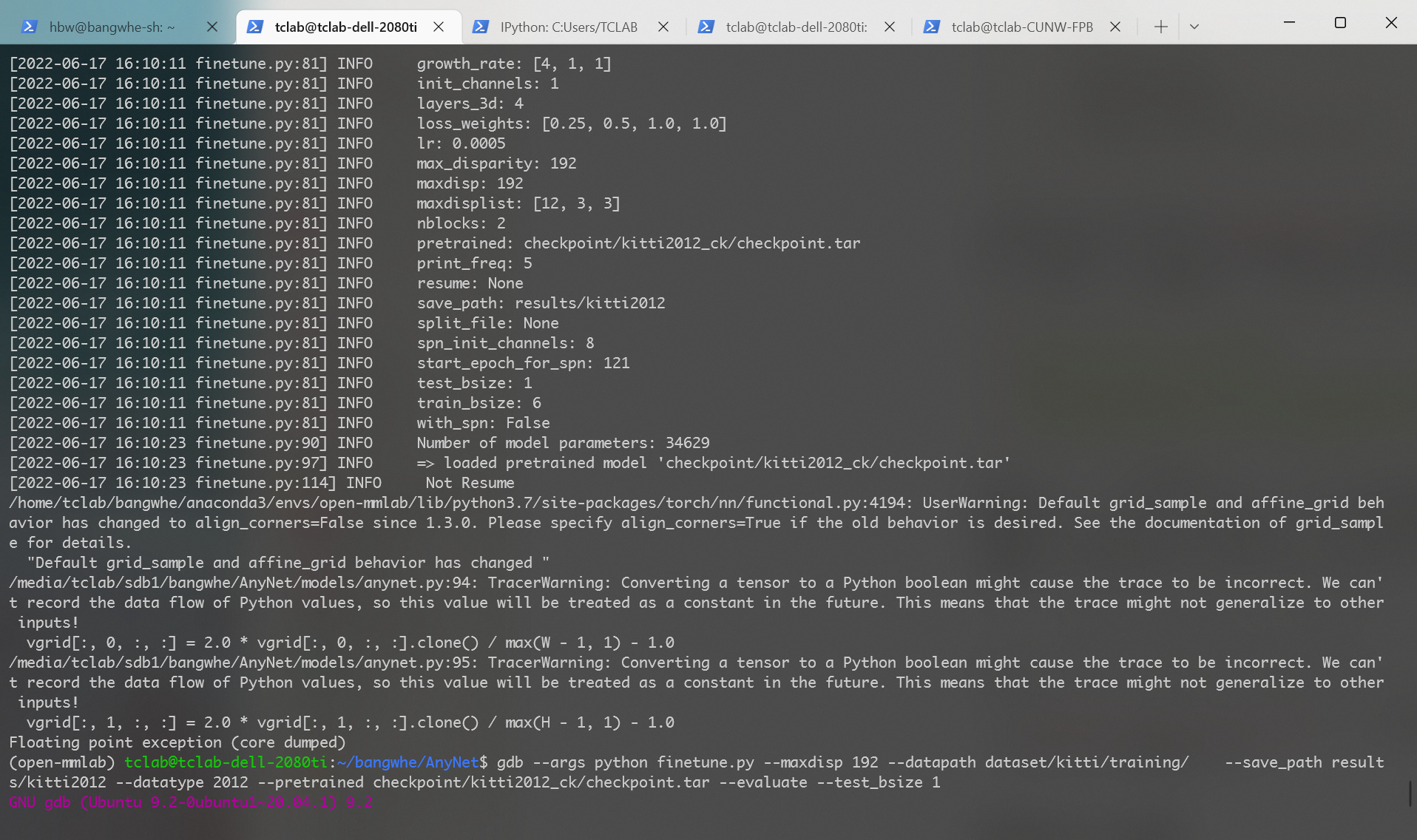
Dealing with floating point exceptions
通过gdb --args python [finetune.py](http://finetune.py) ${params} ,可以查看到更多的报错信息,截图如下:
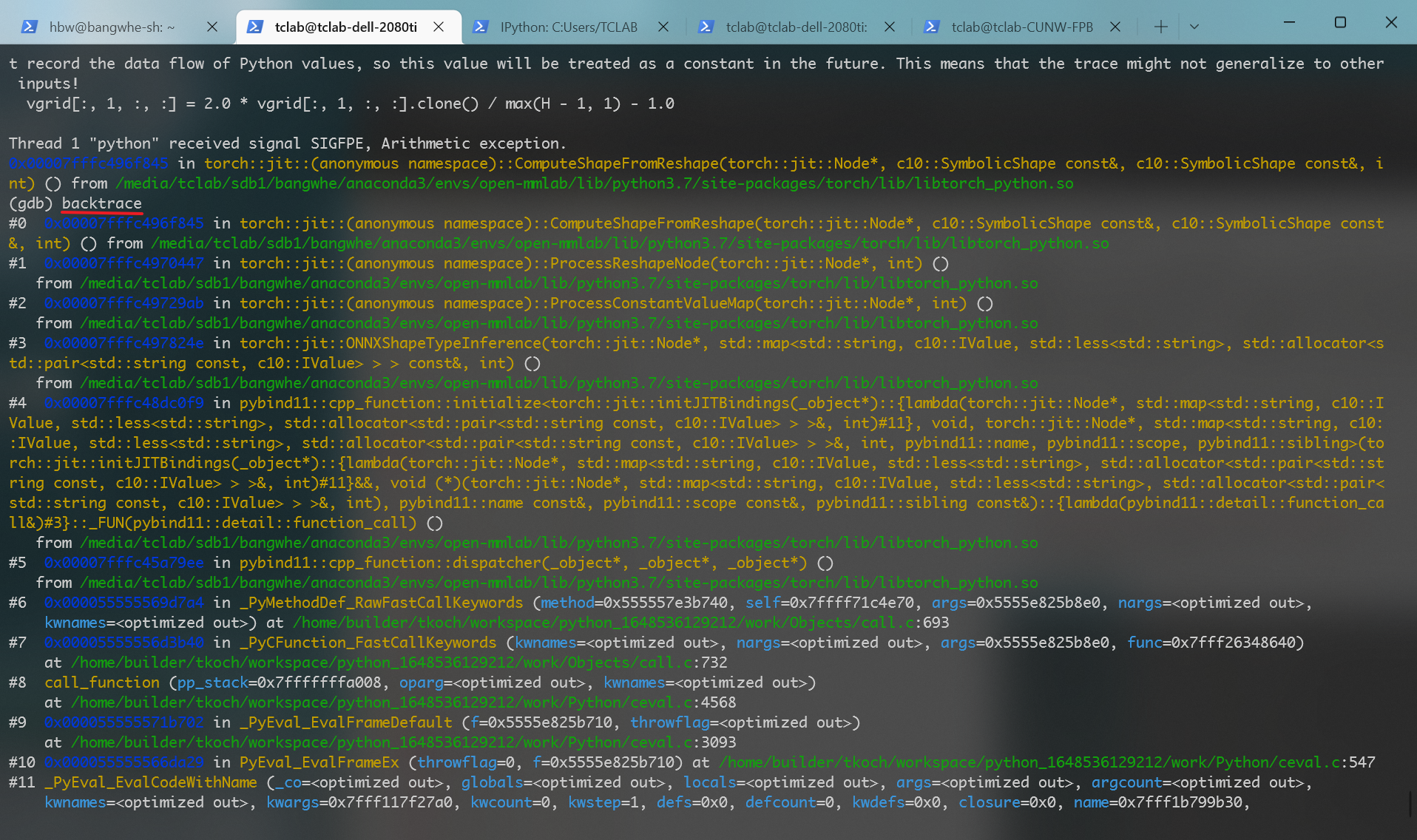
ONNX to ORT
- 除法算子导致张量除法的datatype不对应。
onnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from /media/tclab/980Pro/users/bangwhe/e2ec/gcn.onnx failed:Type Error: Type parameter (T) of Optype (Div) bound to different types (tensor(double) and tensor(float) in node (Div_337).
1 | # 原代码 |
- 循环中的
==生成了bool,可能不受支持。onnxruntime.capi.onnxruntime_pybind11_state.InvalidGraph: [ONNXRuntimeError] : 10 : INVALID_GRAPH : Load model from /media/tclab/980Pro/users/bangwhe/e2ec/gcn.onnx failed:This is an invalid model. Type Error: Type 'tensor(bool)' of input parameter (763) of operator (ScatterND) in node (ScatterND_543) is invalid.
1 | # 原代码 |
ORT NNAPI
https://github.com/BangwenHe/ORTSegDemo
onnxruntime/ScoreMNIST.java at master · microsoft/onnxruntime
onnxruntime-inference-examples/ImageUtil.kt at main · microsoft/onnxruntime-inference-examples
导出成onnx或者ort模型后,部署到手机上肯定是会支持CPU的,但是是否支持GPU还需要看模型的支持或者NNAPI的支持。增加CPU的线程数可以直接使用mSessionOptions.setIntraOpNumThreads(4); ,肯定是支持的。
- shape错误,应该是slice(切片)算子不受到NNAPI的支持。
1 | W/System.err: ai.onnxruntime.OrtException: Error code - ORT_FAIL - |
- 我认为我导出的这个e2ec或者是snake不能运行到mobile端的GPU上应该是因为添加了太多的逻辑运算,而不仅仅是Conv、BN、ReLU这些算子,例如NonZero,还有一些多维取值算子,例如ScatterND、Gather等。这些逻辑算子和取值算子对于逻辑运算单元少的GPU来说,并行起来是非常困难的。所以优化的角度应该是把类似后处理的逻辑运算给提取出来,只保留大部分的backbone,手动从heatmap中提取关键点的位置信息,posenet输出的就是heatmap,需要手动做提取。
Build ONNXRuntime From Source
要求cmake 3.18+,android SDK需要手动通过sdkmanager下载。加上--build_java 会很慢,所以先删掉。
1 | export PATH=/mnt/tbdisk/bangwhe/experiments/cmake-3.20.6-linux-x86_64/bin/:$PATH |
编译得到的so库都保存在build文件夹中,下面有子文件夹,分别保存安卓端和Linux桌面端。
OnnxRuntime C++ Impl
Linux
onnxruntime-inference-examples/model-explorer.cpp at main · microsoft/onnxruntime-inference-examples
error: use of deleted function ‘Ort::Experimental::Session::Session(const Ort::Experimental::Session&) :函数被删除了,后面有debug信息。这个session不能通过函数传到其它的函数里,从而被调用。Ort::Value 也是一样的,但是通过std::move 将其变成右值,就可以传到vector 中。(Why?)
vscode添加索引路径:command palette → C/C++: Edit Configurations (JSON)
2022-08-15 10:50:20.544504982 [W:onnxruntime:, graph.cc:1220 Graph] Initializer 1894 appears in graph inputs and will not be treated as constant value/weight. This may prevent some of the graph optimizations, like const folding. Move it out of graph inputs if there is no need to override it, by either re-generating the model with latest exporter/converter or with the tool onnxruntime/tools/python/remove_initializer_from_input.py. initializer 1894 出现在图形输入中,不会被视为常量值/权重,可能会阻止一些类似常量折叠的优化,可以使用onnxruntime/tools/python/remove_initializer_from_input.py 来进行移除操作。移除前的推理时间是45ms,移除后是19ms,提升还是比较大的。
cv:dnn:blobFromImage 不太好用,经常把320x320的Mat变成3x1的Mat。(Why?)
OpenCV的Mat 类和ORT的Ort::Value 类都可以得到它们的数据指针,方法分别是:
[Mat.data](http://Mat.data)可以直接得到数据的指针,但是更常用的是Mat.at<DataType>()Ort::Value::GetTensorMutableData<DataType>(),得到Ort::Value保存的张量的数据指针- 通过这两个指针,我们可以得到预处理得到的结果和输入网络前的张量的大小。如果需要对比预处理是否相同,可以自己读指针,然后打印数据出来跟python版的数据做对比。
terminate called after throwing an instance of 'Ort::Exception' what(): not enough space: expected 1228800, got 409600 :明显的报错,空间不够。这是因为传入的p_data_element_count 和*shape 的乘积大小不相同,所以导致了报错,传入的参数为102400 和307200 ,再乘上float类型占用的4byte,有409600 和1228800 ,所以商(3)代表少了三个通道,给p_data_element_count 乘上3即可。
incomplete type is not allowed :需要先定义一个type,才能在后续使用这个标识符的时候知道它是啥。这里报错是因为OrtSession这个类(标识符)不存在,需要变成指针类型才可以,即OrtSession*类型。
error: use of deleted function ‘Ort::Session::Session(const Ort::Session&)’ :使用了被删除的拷贝构造函数,所以不能把它当作变量传到某一个函数中,编译器就会报错(为什么会删除呢?参考我的02)。那我们总不可能不用函数吧?在3501行,注释中说:
Prevent users from accidentally copying the API structure, it should always be passed as a pointer.
所以我们应该传入一个指针。从类名往上溯源,发现一个Base 类,它有一个函数:operator T*() { return p_; } ,这个是类型转换的函数,所以我们只需要把Session转换成它的包装类即可,即
1 | getOutputInfo((OrtSession*) session); |
a nonstatic member reference must be relative to a specific object :函数不是静态函数,所以必须通过方法访问。
Android
安卓平台和Linux平台的实现基本上都是一样的,参考我的两个demo:https://github.com/BangwenHe/ORTSegDemo和https://github.com/BangwenHe/ort-snake-cpp。主要的步骤就是编写cmake,通过cmake把预编译的so库链接到项目中。安卓上更需要考虑怎么处理JNI,以及编译的问题。
JNI的影响是jstring到string,long到jlong。
编译:由于java版本和c++版本都有libonnxruntime.so 这个文件,所以如果打包到一起,会导致文件重复而报错。
我写了一个 OnnxRuntime 手机端推理的 Demo,OrtSegDemo。只要能够导出 ONNX 文件,就可以用它在 CPU 上实现推理,GPU 不一定能够成功。下面是用法:
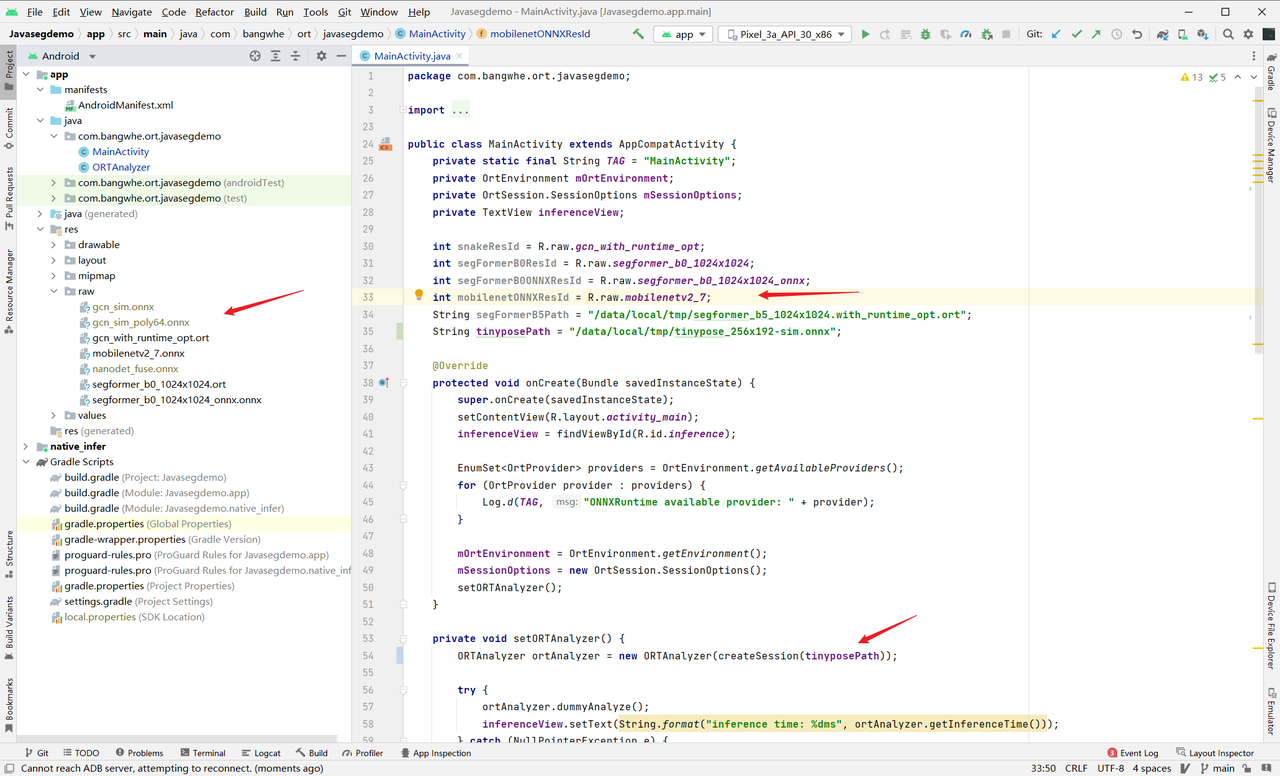
需要修改的地方就是上面三个箭头指向的地方:
- 把导出的 ONNX 模型放到 raw 文件夹中,注意文件名只能由字母、数字和下划线组成
- 添加一个新的 ResId 变量,例如导出的文件名叫做 e2ec_sim.onnx ,那么可以加上一条新的语句:int e2ecId = R.raw.e2ec_sim;
- 修改第 54 行的传入参数,将 tinyposePath 修改成 e2ecId
- 编译运行整个项目
下面是我的运行结果:
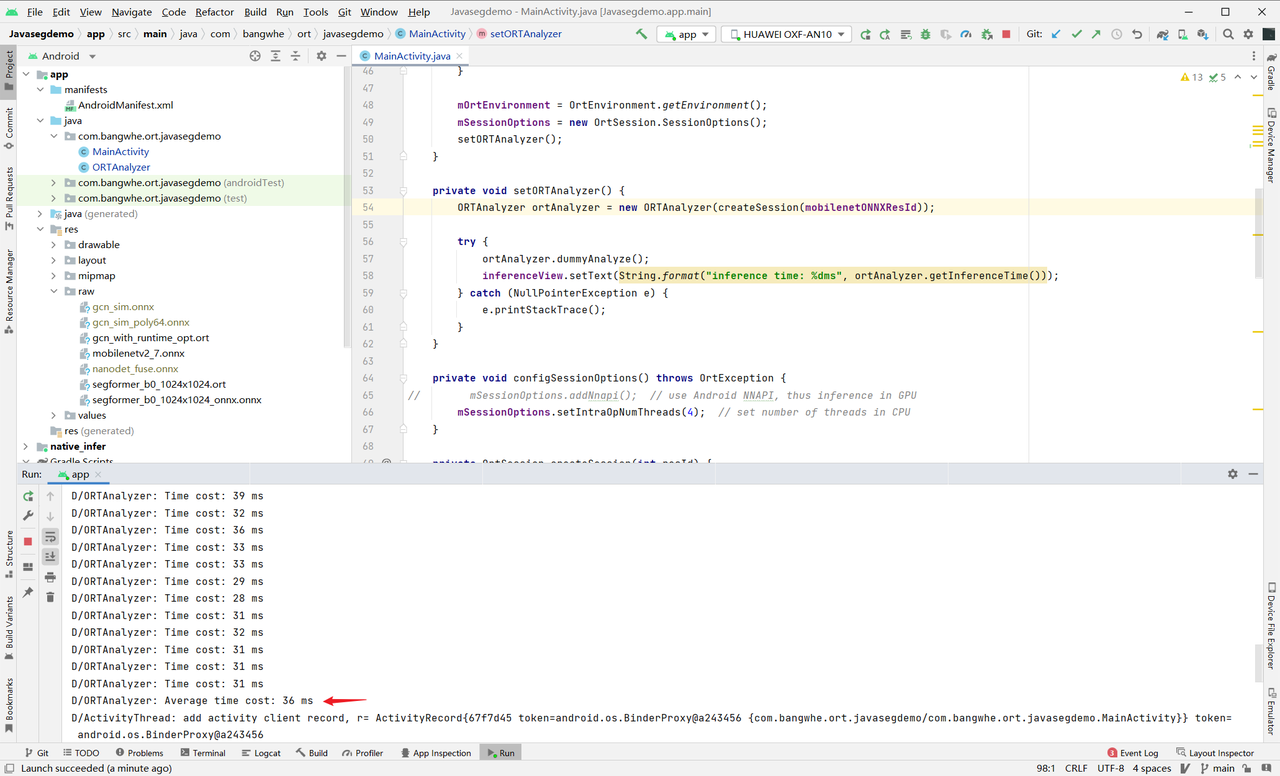
可以看到,最后会显示一个平均延时。
